AI fails again
I was trying to fit a mixed effects model and I waned to compare the model with the same fixed effects with and without a random intercept in an ANOVA. So I wasn’t sure how to do this using lmer from the lme4 package. So I googled it:

It gave me the following answer with code:

# Example data
data <- data.frame(
response = rnorm(100),
fixed_effect_1 = rnorm(100),
fixed_effect_2 = rnorm(100)
)
# Fit a linear mixed model with no random effects
model <- lmer(response ~ fixed_effect_1 + fixed_effect_2, data = data)
# Display the model summary
summary(model)
I was pretty sure this wouldn't work, but I tried it anyway. And it doesn't work. You can't fit an lmer model without specifying random effects. 
For the record, I’m not sure my question even makes sense. I think I should be comparing these models with AIC rather than ANOVA, now that I think about it for more than a second.
Anyway,
Cheers.
However bad you think the Rockies are, they are worse. Even worse than the White Sox last year (so far).
Update: They swept the Marlins and are now on a 3 game winning streak and sit at 12-50. They are 25 games out of first place with 100 games to play.
Update: They won last night and are now 10-50 as of noon on June 3.
The Rockies are 9-50. That’s 50 losses in 59 games. A winning percentage of .153. That’s the fastest any team has gotten to 50 losses since 1901. But didn’t we just get a new worst ever team last year in the Chicago White Sox? Yup! The Chicago White Sox lost 121 games last year, the most ever. And the Rockies are currently on pace to shat. ter. the White Sox loss record from last year. They are currently on pace to go 25-137. How bad is this? At this point in the season, the White sox were 15-44. SIX games ahead of where the Rockies are right now. To see this, let’s look at some data viz that I made.
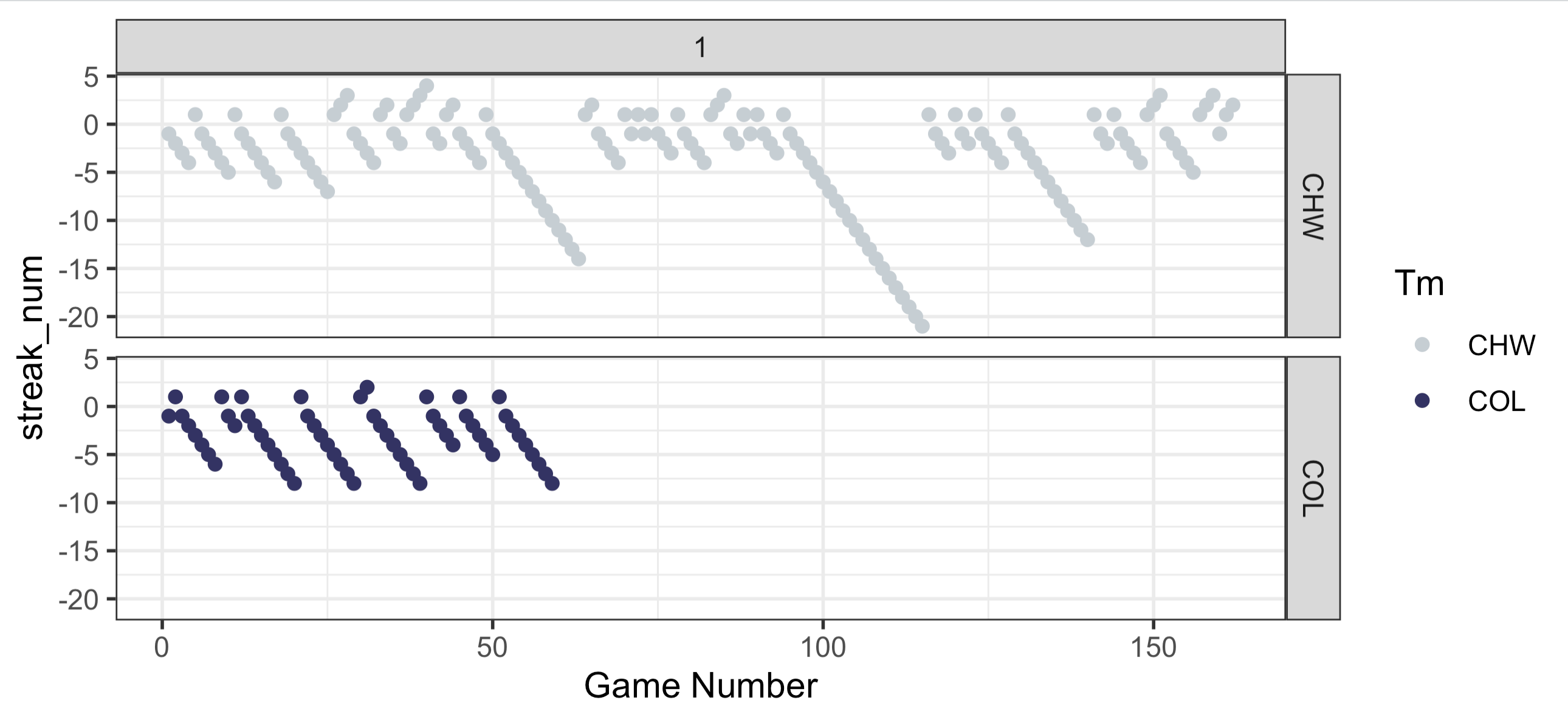
Below is a plot of game number versus cumulative wins. Up until about game 30 the Rockies were merely just as bad as the White Sox. Since then they have really stepped down their game thanks to multiple 8 game losing streaks. Speaking of streaks, let’s take a look at that.

Below, you’ll find a plot of game number on the x axis and the win/loss streak on the y-axis. Positive numbers are winning streaks and negative numbers are losing streaks. You can see that the Rockies have already had FOUR 8 game losing streaks. But even more impressive than that is that they’ve only won back to back games a single time this season. Let me repeat this: Their largest win streak of the season is 2 games and it’s happened exactly once. The White Sox last year has winning streak of 2 or more 9 times total and 4 up to this point in the season,. They even had a nifty little 4 game winning streak (They also had losing streaks of 12, 14, and 21(!!!) games).
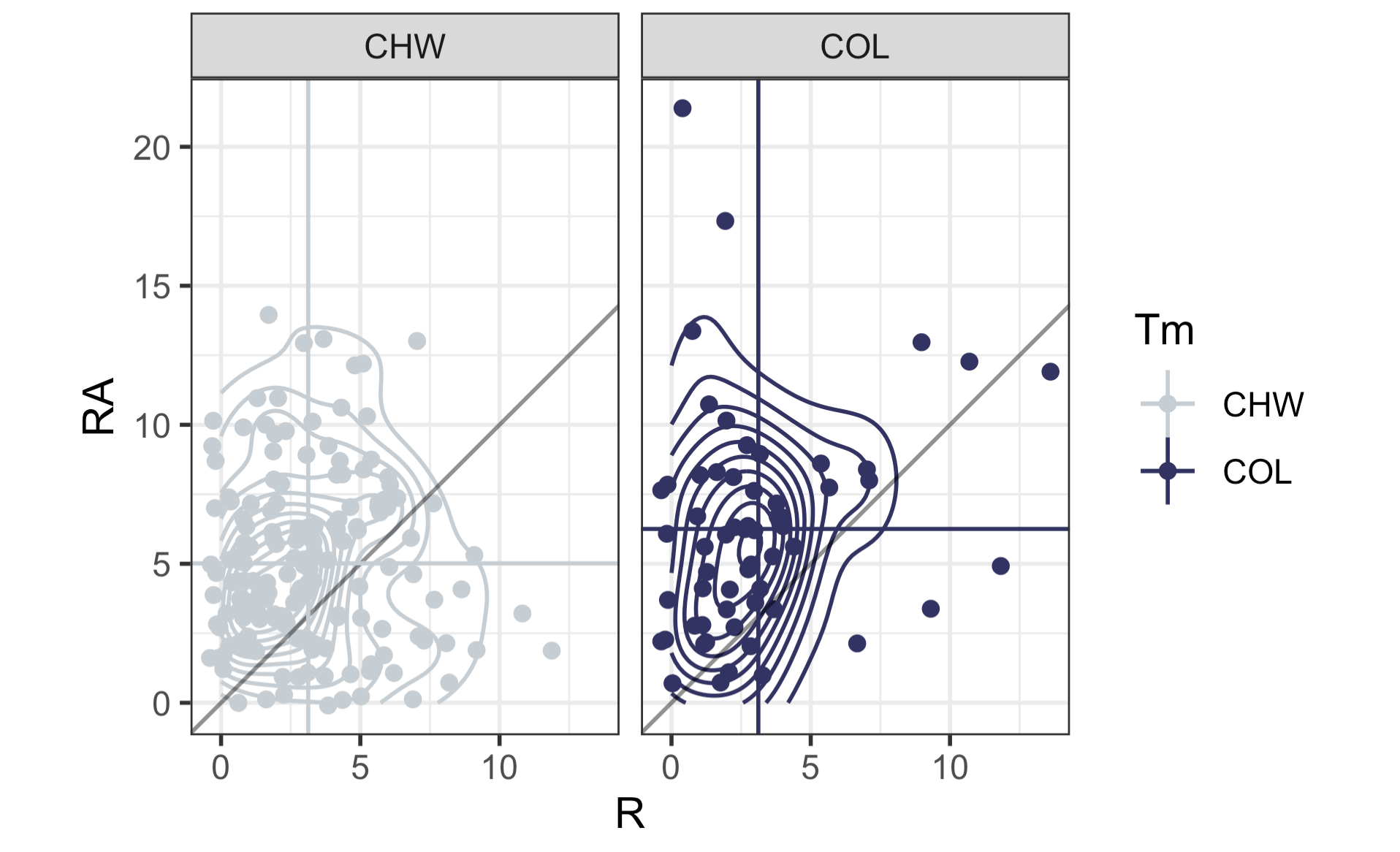
Now let’s take a look at scoring for the Rockies. Below is a 2d contour plot of for the runs for and runs against for every game from the White Sox 2024 season in the left panel and every game of the current Rockies season. The horizontal and vertical lines are the mean number of runs for and against and the diagonal lines shows whether the game was won or lost by the respective team (above the line is a loss, below the line if a win). What’s really interesting about this is that in the entire season last year, the White Sox only score 10 or more runs TWICE. The Rockies have already done this 3 times. Also, the most runs that the White Sox gave up all season was 14 runes. The Rockies have given up more than 14 runs twice already. (a 17-2 loss to the Brewers and a 21-0 loss to the Padres).
Here is what these plots look like on top of one another. What you’ll notice is that it’s hard to see the vertical line for the White Sox (i.e. their mean number of runs) because it’s nearly identical to the Rockies. The White Sox average 3.13 runs per game last year and the Rockies are just slightly below that at 3.12 runs per game. But where Colorado really “shines” is their defense. While the White Sox gave up an average of just over 5 runs per game (5.02, to be exact), the Rockies are currently allowing, and I can’t believe this is true, 6.25 runs per game. That 1.23 more runs per game on average than the worst team in the modern history of baseball. Incredible work.
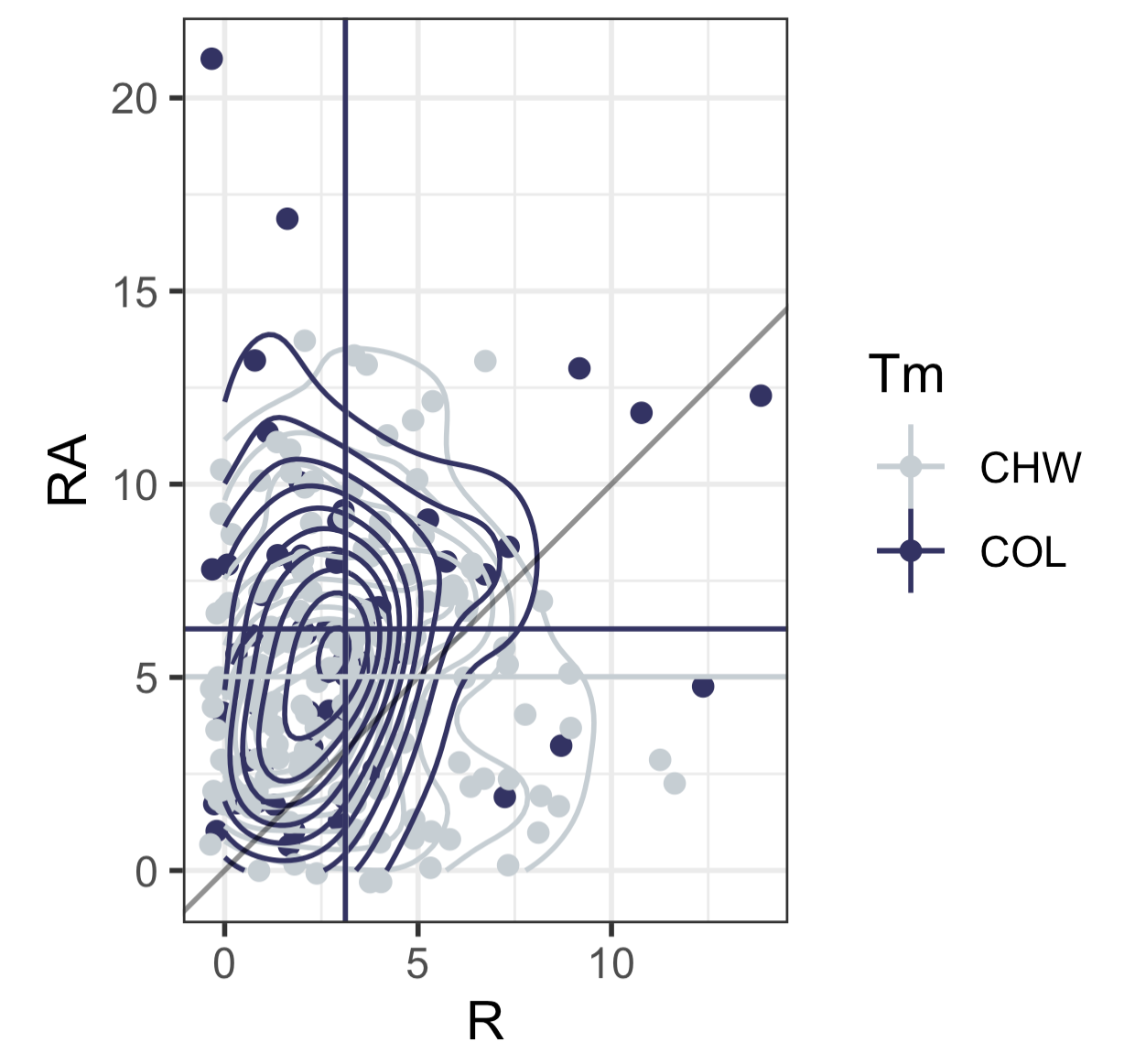
If you’re a median type of person, I computed those two. The White Sox last year scored a median of 3 runs and allowed a median of 5 runs. For the Rockies this year, they are scoring a median of 2 runs and allowing a median of 6 runs.
Anyway, the point is that the Rockies are [really]+ bad.
My code is below.
Cheers.
rock <- read.csv("/Users/gregorymatthews/Dropbox/statsinthewild/rockies2025_20250602.csv")
ws <- read.csv("/Users/gregorymatthews/Dropbox/statsinthewild/whitesox2024.csv")
names(rock)[1] <- names(ws)[1] <- "gameno"
rock$streak_num <- as.numeric(paste0(substring(rock$Streak,1,1),nchar(rock$Streak)))
rock$W <- as.numeric(unlist(lapply(strsplit(rock$W.L.1,"-"),function(x){x[1]})))
rock$L <- as.numeric(unlist(lapply(strsplit(rock$W.L.1,"-"),function(x){x[2]})))
ws$streak_num <- as.numeric(paste0(substring(ws$Streak,1,1),nchar(ws$Streak)))
ws$W <- as.numeric(unlist(lapply(strsplit(ws$W.L.1,"-"),function(x){x[1]})))
ws$L <- as.numeric(unlist(lapply(strsplit(ws$W.L.1,"-"),function(x){x[2]})))
both <- rbind(rock,ws)
library(tidyverse)
library(teamcolors)
small <- teamcolors %>% filter(name %in% c("Chicago White Sox","Colorado Rockies"))
ggplot(aes(x = gameno, y = W,color = Tm), data =both) +
geom_path() +
theme_bw() +
scale_color_manual(values = c(small$secondary[1],small$primary[2])) +
xlab("Game Number")
ggplot(aes(x = gameno, y = streak_num, col = Tm), data = both) + geom_point() + theme_bw() + facet_grid(Tm~1) + scale_color_manual(values = c(small$secondary[1],small$primary[2])) + xlab("Game Number")
ggplot(aes(x = R, y = RA, color = Tm), data = both) +
geom_jitter() +
geom_density2d() +
scale_color_manual(values = c(small$secondary[1],small$primary[2])) +
theme_bw() + geom_abline(slope = 1, color = rgb(0,0,0,.5)) +
geom_vline(aes(xintercept = R, color = Tm), data = both %>% group_by(Tm) %>% summarise(R = mean(R),RA = mean(RA))) +
geom_hline(aes(yintercept = RA, color = Tm), data = both %>% group_by(Tm) %>% summarise(R = mean(R),RA = mean(RA))) + coord_fixed() +
both %>% group_by(Tm) %>% summarise(median(R),median(RA))
both %>% group_by(Tm) %>% summarise(mean(R),mean(RA))
both %>% filter(Tm == "COL") %>% pull(R) %>% table()
both %>% filter(Tm == "CHW") %>% pull(R) %>% table()
Kaggle Probs for sweet sixteen games.
Men’s
Alabama over BYU – 72.1%
Duke over Arizona – 90.3%
Michigan St. over Ole Miss – 78.0%
Tennessee over Kentucky – 76.3%
Florida over Maryland – 90.3%
Texas Tech over Arkansas – 62.4%
Auburn over Michigan – 77.0%
Houston over Michigan – 77.0%
Women’s
South Carolina over Maryland – 96.2%
Duke over North Carolina – 72.1%
UCLA over Ole Miss – 95.8%
LSU over NC State – 29.6%
Texas over Tennessee – 91.8%
TCU over Notre Dame – 50.0%
USC over Kansas St. – 96.2%
UConn over Oklahoma – 96.2%
Cheers.
Kaggle Probs for today’s games – 3/22/2025
Women
Iowa: 80.8%
UConn: 100%
Alabama: 88.5%
West Vriginia: 86.4%
NC State: 100%
Oklahoma: 100%
USC: 100%
Oklahoma St: 72.8%
Maryland: 91.3%
Michigan St: 66.4%
North Carolina: 100%
California: 55.7%
Illinois: 55.7%
Florida St: 66.4%
Texas: 100%
LSU: 100%
Men
Purdue: 58.3%
St. John’s: 82.4%
Texas A&M: 50.0%
Texas Tech: 62.4%
Auburn: 78.3%
Wisconsin: 51.0%
Houston: 73.9%
Tennessee: 82.4%
Cheers.
NCAA Probs
Yo. It’s been a while.
Here are my win probabilities for the games today from my kaggle entry this year.
Creighton: 40.6%
Purdue: 75.7%
Wisconsin: 92.4%
Houston: 100%
Auburn: 100%
Clemson: 75.7%
BYU: 59.36%
Gonzaga: 72.8%
Tennessee: 100%
Missouri: 72.8%
UCLA: 69.7%
St. John’s: 94.3%
Michigan: 59.4%
Texas Tech: 89.999566%
Kansas: 69.7%
Texas A&M: 75.7%
Cheers.
Live blogging the 2024 presidential election
2:54am Central Time:
So, uh, what went wrong in that Selzer poll?
10:32pm Central Time:
Just got back from my run. What are we doing America? What the fuck are we doing? The next four years are going to be so bad. So much worse than you can even imagine. It’s just. so. stupid. Good night. I’m gonna go watch a documentary about aliens and then smash my face through a window.
9:24pm Central Time:
I still haven’t gone running. But I haven’t checked the race in a while. It looks much worse than it did before. What the fuck are we doing America? You think this guy is gonna save the economy? Jesus. Christ.
8:27pm Central Time:
I’m going running.
8:18pm Central Time:
It’s just past quarter past 8. Nothing terribly surprising has happened so far. NYT gives Trump a 66% chance to win.

7:54pm Central Time:
Is there ANY other election in the world where the person with the most votes can lose the election? Or is it only the election to pick the most powerful person in the world?
7:44pm Central Time:
The NYT gives Trump a 53% chance to win Pennsylvania. But that prediction right now is based only on pre-election polls and their “model”. Nothing to do with actual results yet. Why even report this?

7:42pm Central Time:
I still think Harris is gonna win Pennsylvania. But it’s gonna be really, really close.
7:36pm Central Time:
Sometimes I reflect on how stupid it is that a few thousand people in Pennsylvania who probably can’t find Canada on a map get to decide who the most powerful person in the world is. Everything is so stupid.
7:35pm Central Time:
Virginia looks to be much closer than it was in 2020. That’s a good sign for Trump. How wild would it be if just everyone got this race completely wrong and Trump wins a place like Virginia and Harris wins something like Iowa or Ohio?
7:27pm Central Time:
In 2023, the Census estimates that about 44000 people from Georgia moved to Florida, around 26000 Michiganders moved to Florida, and about 28000 Pennsylvanians moved to Florida. And something like 9000 people from Wisconsin moved to Florida. Again, based on nothing, I’m guessing thats a vast majority of these people were right leaning. Would it make sense then that all these states get slightly bluer and Texas and Florida get slightly redder?
7:16pm Central Time:
Crazy theory based on nothing: Enough right leaning voters moved to Texas and Florida from swing states in the last 4 years that Trump’s margin in Florida and Texas will beat his margin’s in those states relative to 2020. But all those people leaving give Harris safe wins in swing states like Pennsylvania, Michigan, and Wisconsin (and Iowa?).
7:08pm Central Time:
New York Times has a much better data presentation than NBC News for election results. Great work NYT.
6:55pm Central Time:
Florida — already America’s inner thigh — continues to get redder and redder. And also it’s shifted further right. (“How the pandemic turned Florida red”)
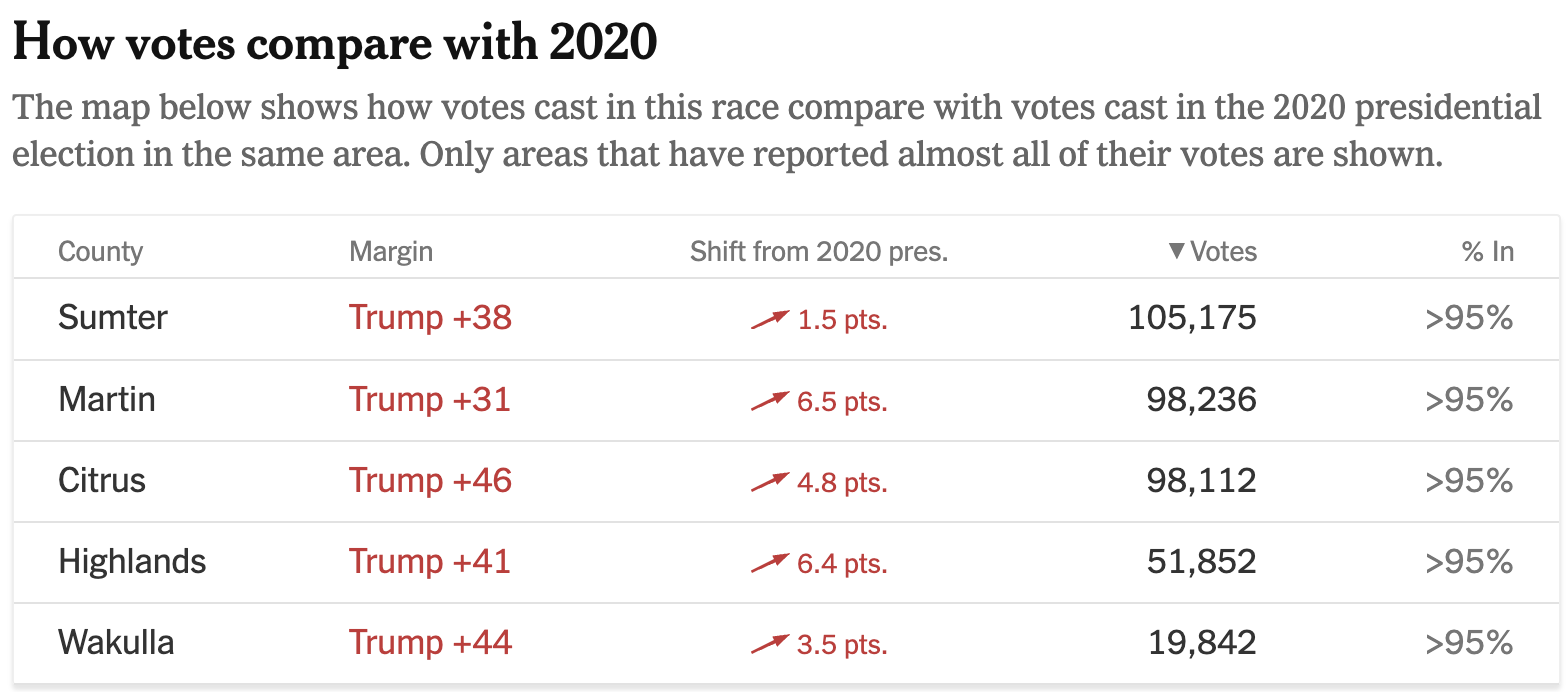
6:44pm Central Time:
I’m seeing the same thing in Georgia as I saw in Indiana: Substantial shifts towards Harris in the suburbs.
For reference, Harris won Douglas County by 25.1% in 2020 and Rockdale by 40.77%. That’s about +7 and +11 with about 70% reporting. Trump in 2020 won Houston, Bartow, Oconee, and Troup by 12.42%, 50.67%, 33.47%, and 21.84%, respectively. That’s shifts of about 1, 0 , -2, and -5 for Trump. He’s about the same in counties he won last time in Georgia, but there are pretty big shifts in the Atlanta suburbs.

6:33pm Central Time:
Trump up 23-3. Kentucky, Indiana, and West Virginia for Trump; Vermont for Kamala. (Can we stop and think about how fucking weird Vermont is for a second?)
6:28pm Central Time:
Going back to Hamilton and Boone County. In 2016, Trump won Boone county by 29.12% and Hamilton by 19.32%. (Note: Boone has 91% of counties reported and Hamilton has 65%). But Trumps support in the Indianapolis suburbs has absolutely cratered since 2016.

6:18pm Central Time:
And…..they’ve called Vermont. Harris is on the board with 3 points. Trump leads 19-3.
6:16pm Central Time:
The north suburbs of Indianapolis are shifting about 8ish points towards Harris so far. That feels like a big deal to me.
- Boone County 2020: Trump by 18.38%
- Boone County 2024 (91% reporting): Trump by 10%
- Hamilton County 2020: Trump by 6.78%
- Hamilton County 2024 (65% reporting): HARRIS by 1.2%
My completely uninformed prediction for the election
I’m a guy on the internet. So naturally I have uninformed opinions. And because this is the internet, I’d like to share them with everyone because….well, what’s the point of the internet if I can’t post uninformed opinions? So here I go.
Here’s what I’ve been looking at recently. I took the polls that fivethirtyeight has listed and I took only the polls that have a grade of 2.5 or higher. I aggregated each of those polls to get a single prediction based on pooling all the polls in a sliding 15 day period. I then bootstrapped some error clouds around these predicted lines and you get the following results for swing states (plus a few bonus states) if you use polls for registered voters:
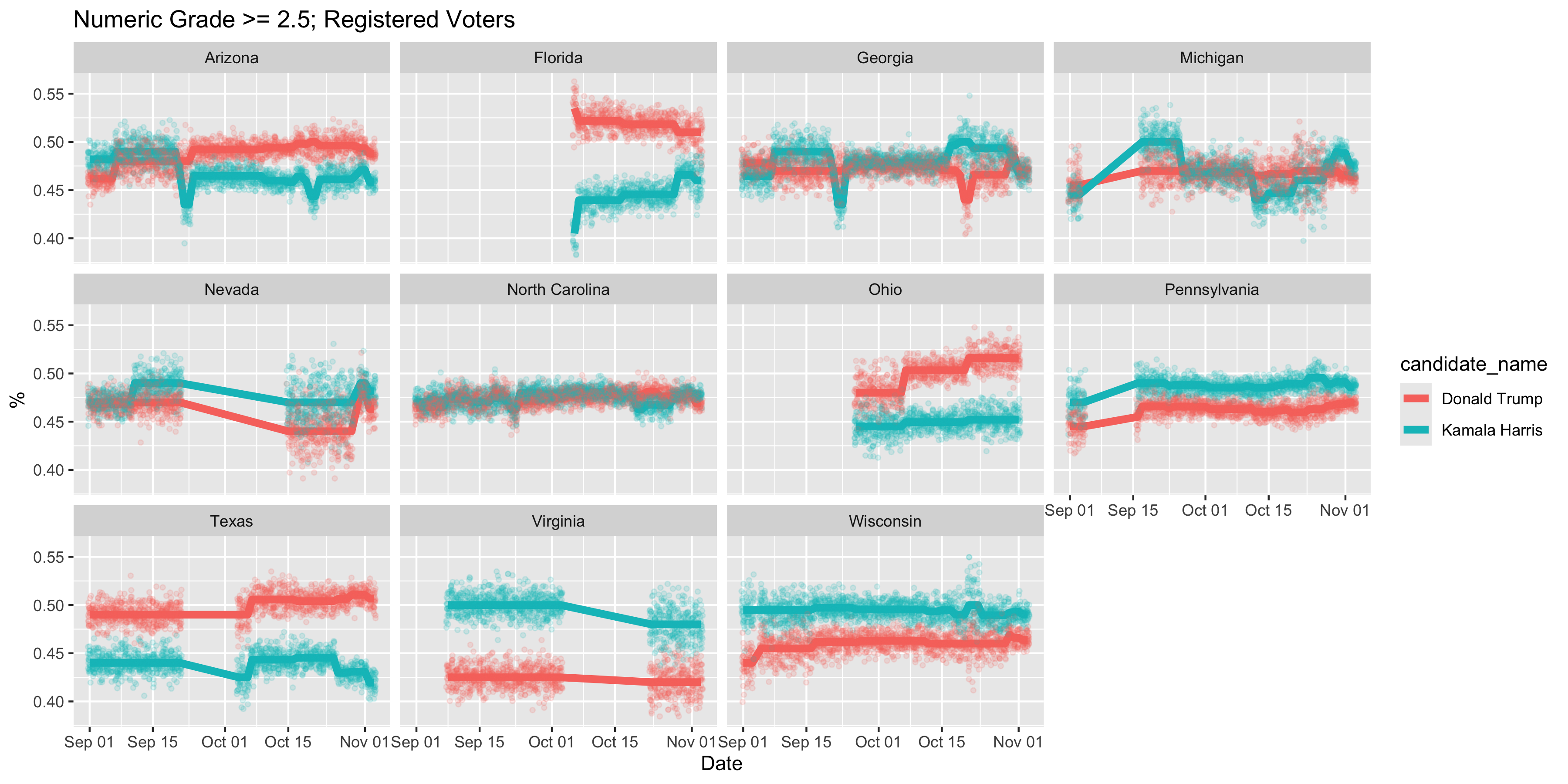
Based on these results, it looks like Pennsylvania and Wisconsin aren’t all that close and Harris has had them locked up for weeks with very little movement at all. Whereas the other swing states, Georgia, Michigan, Nevada, and North Carolina all seem incredibly close. Which gives up basically this map:

With this map all Kamala needs to win is one of Michigan and Nevada OR North Carolina OR Georgia. But if we look at likely voters, the story is different. (How do they determine likely voters? Do they ask respondents? Or do they model that?).
Here, Georgia is safely in Trumps column but the other five swing states are all statistically tied.
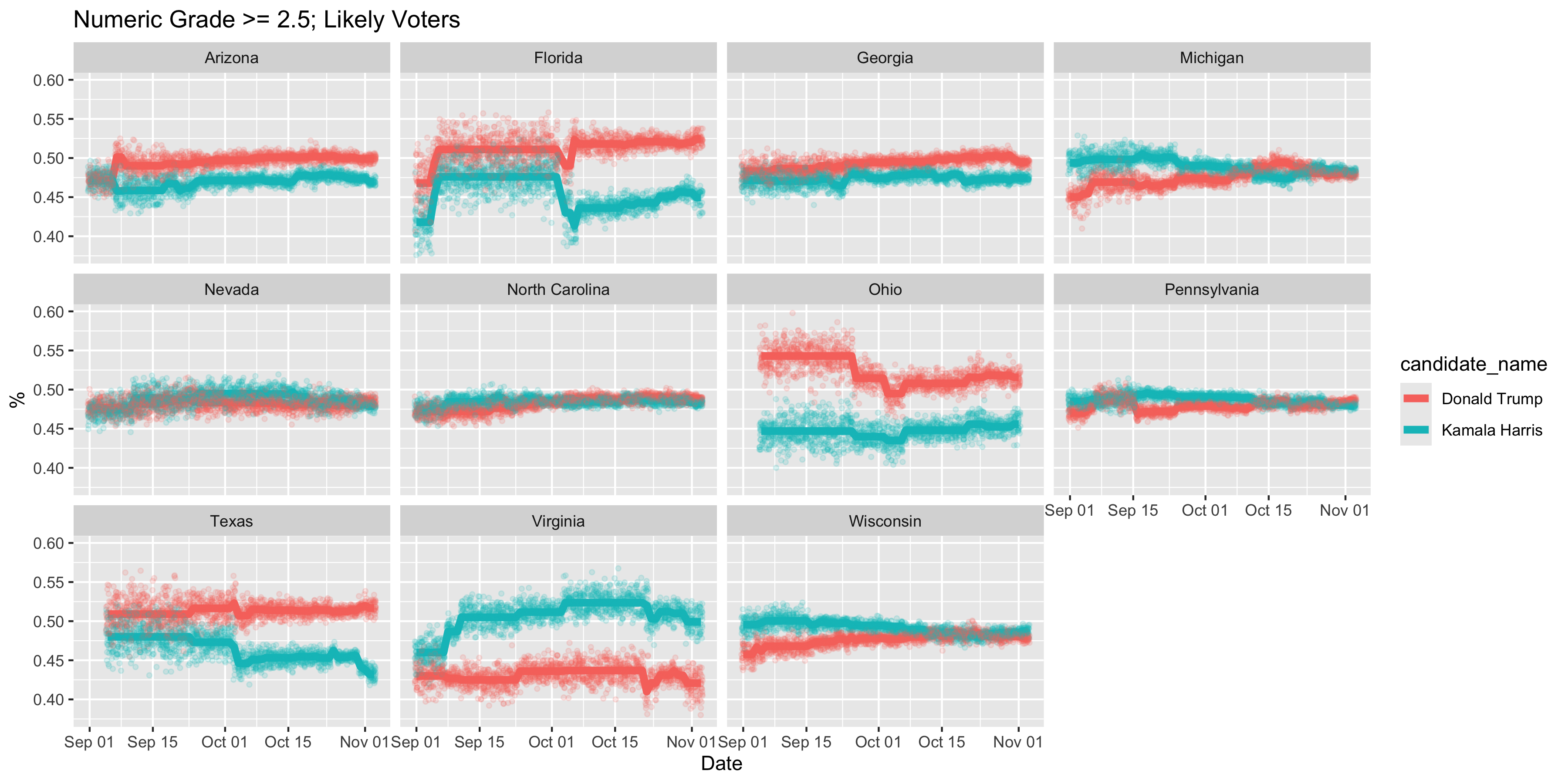
This would give us this map:
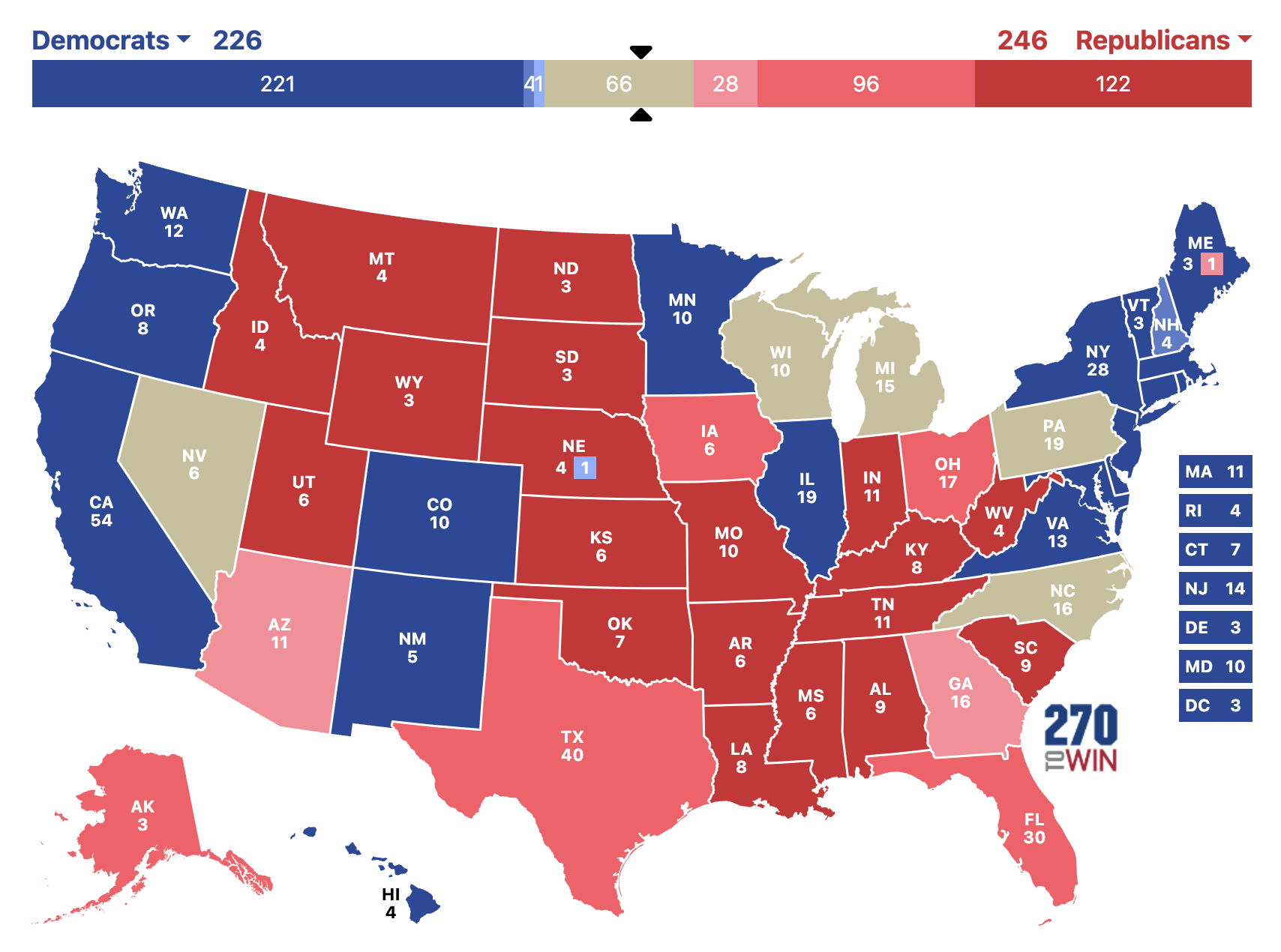
And this would mean all Trump needs to do to win would be to win any two of Wisconsin, Michigan, Pennsylvania, and North Carolina. But you didn’t come here for insight or rational discussion. This is the presidential race in 2024 where facts don’t matter and numbers are just completely made up. So what do I think will happen? I present to you my official completely uninformed prediction for the 2024 presidential race. I think Kamala wins the popular vote by 3 points and we end up with this map. And she wins by two electoral votes (and then there are 3 faithless electors and Trump wins anyway because….everything is stupid).
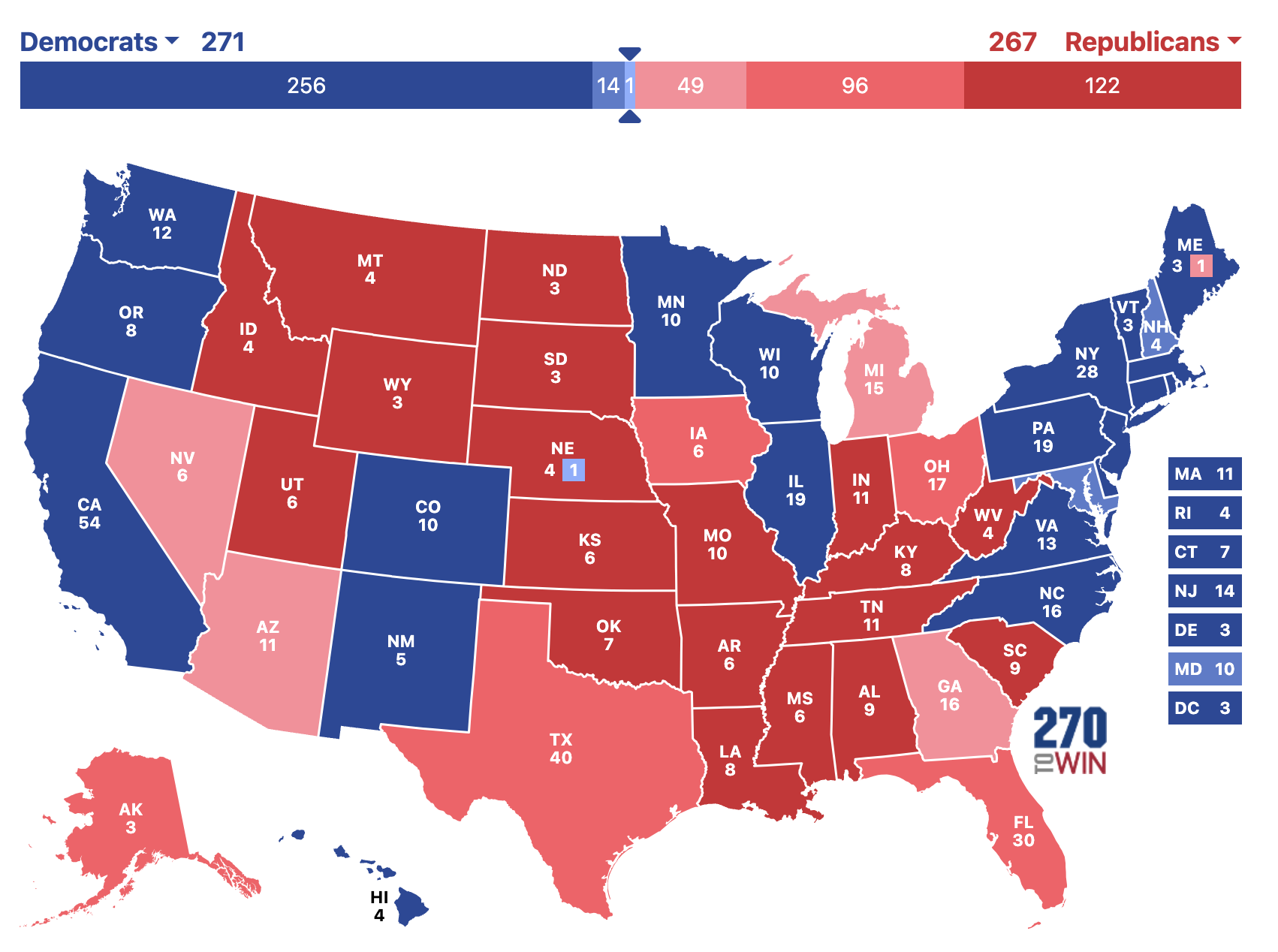
In all seriousness, no one knows what is going to happen. And polling is incredibly complicated in 2024. Response rates for polls used to be in the SIXTIES. Today? It’s less than 1 percent. I think about this all the time, think about this question: “Is it even possible for a pollster to reach you?”. For me the answer is 100% no. I don’t have a land line and I’m not answering my cell phone for a number I don’t know. I’m not gonna respond to an email from a pollster. So I genuinely will never be a poll responded. Now think about how true this is for everyone you know. Polling in 2024 is really difficult. That’s why even with all this polling we still have no idea who’s going to win. It is important to note than in both 2016 and 2020 Trump was underestimated in polls. Pollsters have attempted to correct for this by using something called “recall-vote weighting” which “in practice inflates Trump’s support”. So it’s very likely that Trump’s support is being over-estimated in many of these polls. And if it’s even slightly over estimated by even a point or two, Trump is going to lose very badly. But it might work! No one knows!
But I’m not a coward like Nate Silver, so I’m making a prediction: I’m taking Kamala 271 to 267. But also I am a coward and Trump might win. I have no idea what’s going to happen. But, rest assured, it will all end with chaos no matter who wins.
Cheers.
John Stewart is wrong and Joe Rogan is right (mostly).
Just a quick note unrelated to statistics.
Tony Hinchcliffe recently made a “joke” about Puerto Rico that might sway the 2024 election. And People are really mad. Hinchcliffe is being universally trashed (see what I did there) over this. But he has an unlikely defender: Jon Stewart. But Jon Stewart is wrong.
Choosing to think Tony Hinchcliffe is funny or not is a matter of personal taste. (I personally think he’s terrible, but that’s just one old man’s opinion). But the larger issue here is that context matters. Tony Hinchcliffe wasn’t on a comedy stage. He wasn’t on a celebrity roast. He wasn’t recording a comedy podcast. He was at a politically rally (A politically rally, mind you, for a guy who was recently called a fascist by an actual retired US general. That’s no small thing).
The context matters! And Joe Rogan somehow knows this better than liberal hero Jon Stewart. While Rogan also defend Hinchcliffe, he also claims he told Hinchcliffe: “It’s a political rally, and you’re doing jokes like you’re in a comedy club. Don’t do it!”
(Rogan goes on to say: “I’ve gotta tell you, that joke kills at comedy clubs. I don’t like the joke, but it kills.” What the fuck?!!?!? That joke KILLS? It’s genuinely a bad joke. It doesn’t even make sense. I don’t even understand why it’s a joke. The only way I can even conceive of it being funny is if you have some pretty terrible feelings about Puerto Rico and Puerto Ricans.)
My point is this: I’m so sick of these right wing “comedians” spewing the most racist hateful shit you’ve ever heard and then hiding behind: “It’s just a joke” and “People are so easily offended these days”. Fucking. Stop.
Finally, I think Sean O’Connor sums up the entire situation better than anyone possibly could:

Cheers.
I have no idea who is going to win, but I’d rather be Kamala than Trump right now (despite what the markets and poll aggregators are saying).
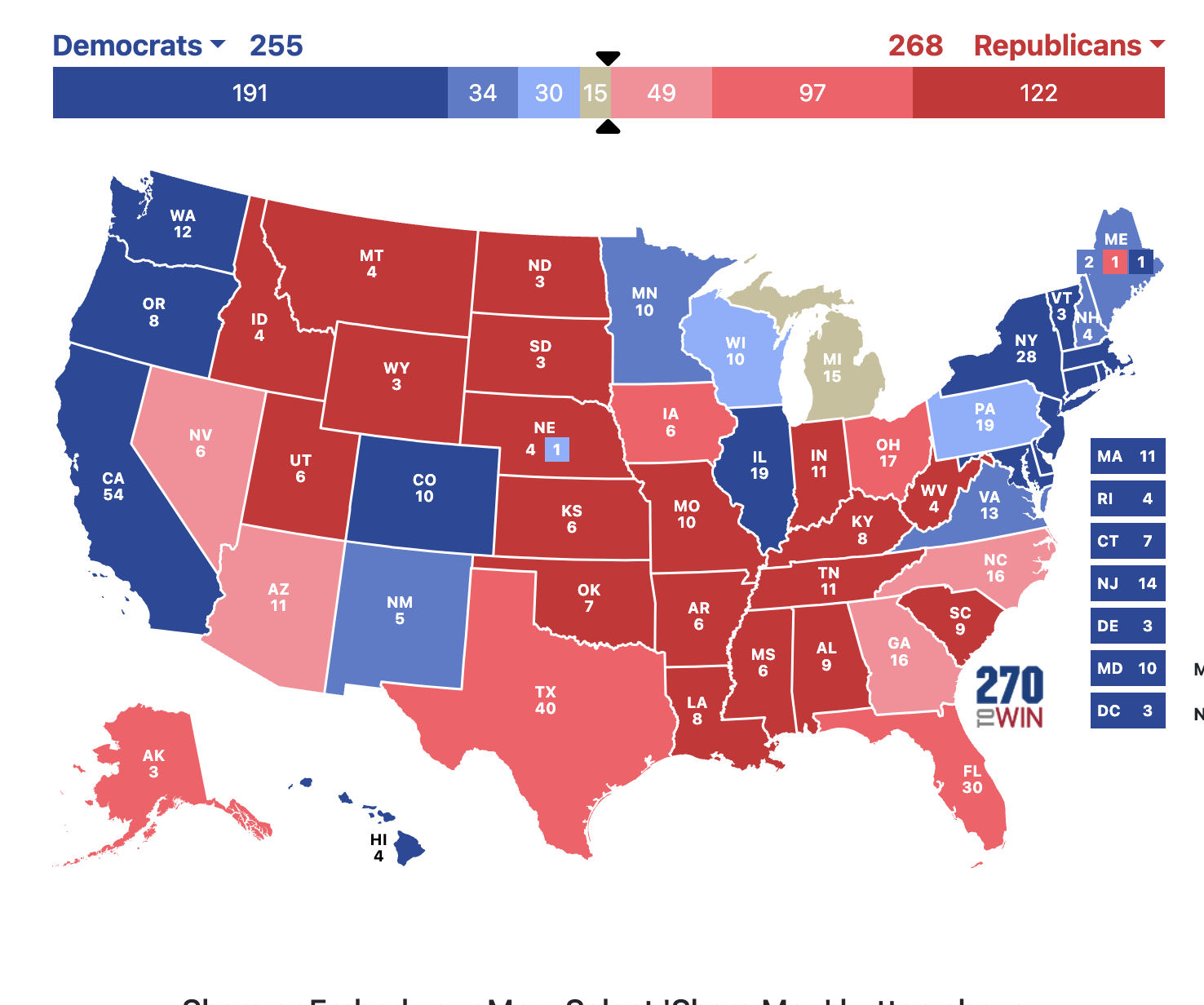
So, there are less than two weeks until election day and Trump is “leading”. FiveThirtyEight gives Trump a 54% chance to win the election. And betting markets also have Trump as a favorite to win (Polymarket gives Trump a 66.1% chance to win). And Trump might win. But…..I don’t see it. I think I’d rather be Harris right now than Trump. (But also I’m always wrong.)


Let’s take a look at Michigan as an example. Polymarket has Trump with a 53% chance to win and FiveThirtyEight has Michigan tied (with Harris leading by 0.4% in their poll aggregator.

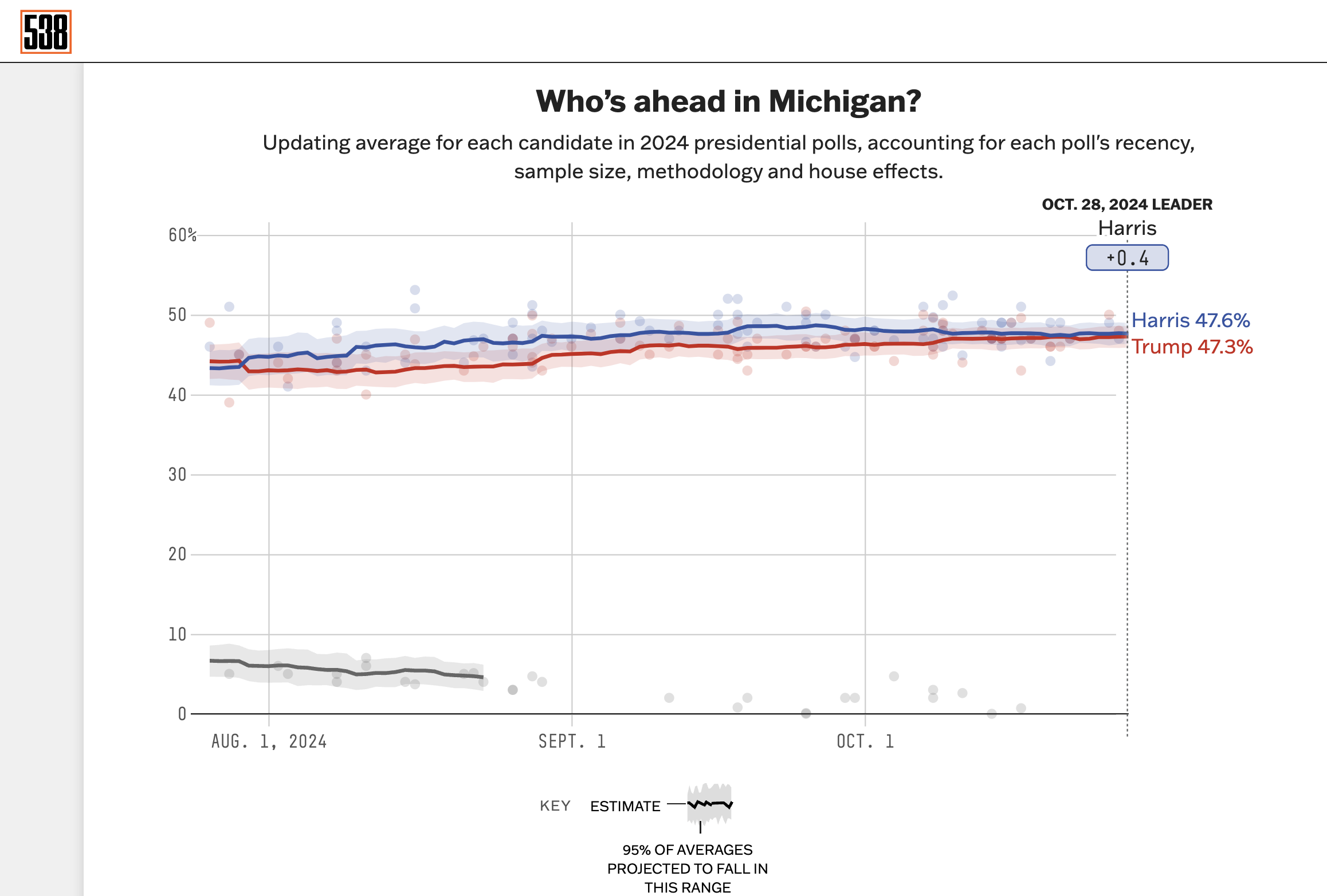
But when you dig into the most recent polls, there is a wildly different story. Take a look at the polls that FiveThirtyEight lists from Oct 16 through today. There are six different polling companies listed here. Two of these six have Harris leading just at about the margin of error (Quinnipiac and Bloomberg). According to FiveThirtyEight’s ranking of pollsters, based on their track record of accuracy, Quinnipiac is 2.8/3 and Morning Consult (for Bloomberg) is 1.9/3. The other four polls listed here are Trafalgar Group, The Telegraph, Patriot Polling, and InsiderAdvantange, which all have Trump tied or leading. One of these, Trafalgar Group, is designated by FiveThirtyEight as “Republican-funded” and known to skew red.

The other three are:
- The Daily Telegraph: A British Conservative newspaper that endorsed Boris Johnson in 2019. (This polls was conducted by Redfield and Wilton Strategies which is rated 1.8/3 by FiveThirtyEight).
- Patriot Polling: A “non-partisan organization” that was literally founded by high school students and has a FiveThirtyEight rating of 1.1/3.
- Insider Advantage: The founder of this company was the on air pollster for Sean Hannity. FiveThirtyEight gives this polling company a 2/3.

So, all I’m trying to say is that the polls that have been flooding the news recently are openly partisan and right leaning. If you look at only the top rated pollster in the rankings from FiveThirtyEight (Siena College), the story from them is different than the Polymarket map in two big ways: Wisconsin and Pennsylvania. Siena College has Harris leading in both those states and kind of comfortably leading in Pennsylvania. In this scenario, it all comes down to Michigan which has flip flopped between blue and red in the last two elections. But factor in that in the Senate race that Slotkin, the Democrat, is leading by 4-5 points, which is advantage Harris. I just have a. hard time imagining a huge number of people voting for Slotkin and Trump. But who knows. I’m always wrong.
The point is this: Boy howdy, this is going to be close. Buckle up and strap in because we aren’t gonna now who won for days (weeks?) after election night. But I’d rather be Harris right now than Trump.
Cheers.
