Category Archives: Uncategorized
Part II: Thriving in a graduate program in statistics
(Note: This is the second in a series about graduate life in statistics. For links to all articles in the series, click here).
Here are the best pieces of advice that I can give someone currently involved in a biostatistics or statistics graduate program.
1- Know your interests, and exploit them
Did you sit through a martingale theory lecture and talk excitedly to the professor afterwards? Or, instead, did you start to think you that you would have been better off as an actuary?
These type of gut feelings are useful when it comes to one of the most stressful periods of a graduate student’s career – picking a research topic. My best advice is to (i) find the type of methods papers in statistics journals that you actually enjoy reading, (ii) find a faculty member capable of leading a thesis or dissertation in this…
View original post 1,032 more words
Part I: Deciding on a graduate program in statistics
(Note: This is first in a three part series about graduate life in statistics. For links to all articles in the series, click here).
Here are some key points to consider when choosing graduate programs in statistics and biostatistics.
1. What’s the difference between biostatistics & statistics?
When I first applied for masters programs in statistics, I had little to no idea what biostatistics was. To the untrained eye – in my case, a liberal arts undergraduate student – the subject biostatistics gave off a connotation aligned with phylums and petri dishes, things I had been hoping to avoid since roughly 10th grade.
Ironically, however, biostatistics is not the intersection of statistics and biology; instead, biostatistics is mostly just statistics applied to fields within or related to public health. In four years of a biostatistics program, for example, I didn’t take a single biology course…
View original post 1,294 more words
My experience with grad school in statistics
In honor of @StatsByLopez‘s upcoming series “So you want a graduate degree in staitstics”, which I will be contributing too, I’ve written a brief history of my graduate school experience.
When I was almost finished with my undergraduate degree at WPI, I got to do a senior project about ranking athletes and sports teams. It was my first exposure to logistic regression (I had very little understanding of what was actually going on). But I absolutely fell in love with the project. Which led me to fall in love with statistics.
I was on pace to finish my bachelor’s degree in 3 years (not a big deal), but I wanted to do something to postpone the real world for at least another year (as any rational 20 year old would do.) So I applied to graduate school in applied statistics at WPI. I was equal parts really interested in statistics, really interested in not getting a job yet, and really unprepared for graduate school.
I struggled through 2 years of mathematical statistics, bayesian analysis, linear regression, etc. And I graduated with a less than impressive GPA, but the important part is that I graduated. Towards the end of my time at WPI remember having a conversation with my advisor and I told him that I wanted to go on and do a Ph.D. I assume he thought I was nuts because I hadn’t exactly dominated my way through the program. But he never told me I shouldn’t go. He did tell me that I didn’t need a Ph.D. to work in industry. (Which is solid advice.)
I moved on and worked for 2 years in a direct marketing department of a major catalog company building predictive models. When I first started working their I was really excited to build these predictive models. I thought it was so cool (and I still think it’s cool) that you can take data from the past to help you better predict the future. So I asked where the data was. My boss told me it was here. And there. And over here. And also over there, but you had to modify that before you used it. And a lot of it was missing. I thought to myself “Where is the rectangular file with no missing data? I want to build models.” Ahh young Gregory you were so cute. I spent much of my time cleaning and organizing the data, and relatively little actually building the models. But you absolutely need to understand the modeling pieces to do the cleaning and organizing well. Other wise you don’t really know or understand what data you (might) need.
After about a year I had had enough and wanted to go back to school for a Ph.D. in statistics. I wanted to teach statistics and have more control over the type of work that I was doing. I applied to several programs and told myself that I wasn’t going to go unless I got funding. I got into 2 schools right away, but neither was willing to commit to funding. I was pretty disappointed. But at the last moment UConn came through with full funding for me. I was in. Go Huskies?
So after two years in the “real world” I went back to cocoon of academia. I also went back to being broke. Not college broke. But like regular adult broke. (I probably took a 50% pay cut going back to grad school).
I was 25 when I returned to grad school. And let me tell you, 25 is a lot different than 21. For instance, I never skipped a class in grad school at UConn to go to a fraternity event. School is a totally different experience after you’ve worked a full time, 40 hour a week job. You should treat grad school like this (except it’s probably 60 hours a week). After 3 semesters, I passed my qualifying exam, and I finished all of my exams and classes in 3 years. In total Uconn took four years to finish since I was doing research from day 1 (Expect more like 5 or 6 years (or 7 or 8) if you come in without a master’s degree). I graduated and did a post-doc at UMass in genetics, and just recently hit the academic job market lottery and landed a position at Loyola University Chicago. I can’t wait to start.
While this post has been mostly a bio of my experience, my piece on StatsByLopez will contain more of my thoughts on what grad school was like for me and what advice I would give to someone else in grad school for statistics.
Cheers.
Great Spam Comment
My newest favorite spam comment:
But this other man, Jesus Christ, brought forgiveness to
a lot of through God’s bountiful gift. ‘ Whirlpool:
Poseidon summons a whirlpool at his ground target location that cripples targets, preventing movement abilities, and pulls
targets toward the center dealing magical damage every.
The contestant must choose the word that matches the definition.
Cheers.
Permutation tests in R
Permuation tests (also called randomization or re-randomization tests) have been around for a long time, but it took the advent of high-speed computers to make them practically available. They can be particularly useful when your data are sampled from unkown distributions, when sample sizes are small, or when outliers are present.
R has two powerful packages for permutation tests – the coin package and the lmPerm package. In this post, we will take a look at the later.
The lmPerm package provides permutation tests for linear models and is particularly easy to impliment. You can use it for all manner of ANOVA/ANCOVA designs, as well as simple, polynomial, and multiple regression. Simply use lmp() and aovp() where you would have used lm() and aov().
Example
Consider the following analysis of covariance senario. Seventy five pregnant mice are divided into four groups and each group receives a different drug dosage (0…
View original post 340 more words
Cleveland Odds to win Championship with Lebron James announcement
Check out this sweet graph from Todd W. Schneider.  Cheers.
Cheers.
Postscript: 538’s World Cup picks
While Nate Silver’s FiveThirtyEight website still has some work to do to meet its high expectations, the site gave the World Cup a pretty strong effort. This included in-depth features on important players, comparisons of numbers from this year’s tournament to past ones, and lots of work regarding the United States’ run into the knockout round.
Excluding the “Weekly round-up” posts, the site posted a pretty remarkable 88 World Cup articles in the past 35 days, or roughly 2.5 per day.
In any case, one of the most popular features of 538 over the past several weeks has been its game picks, in which Nate’s statistical model generates game outcome probabilities. For the group stage, this entailed three-way probabilities (allowing for the possibility of ties), and for the knockout stage, 538’s model gave a probability for each team advancing.
Given the model’s fascination with Brazil, and the home…
View original post 381 more words
Golf with my old man
For the last 7 years I’ve been going to Vermont with my father to golf. For the last 5 we’ve had a contest where we take the lowest score on each hole from our 7 rounds to complete our “master card”. Below is a visualization of the contest last year. I made up a ton of ground in the last round, but to no avail.
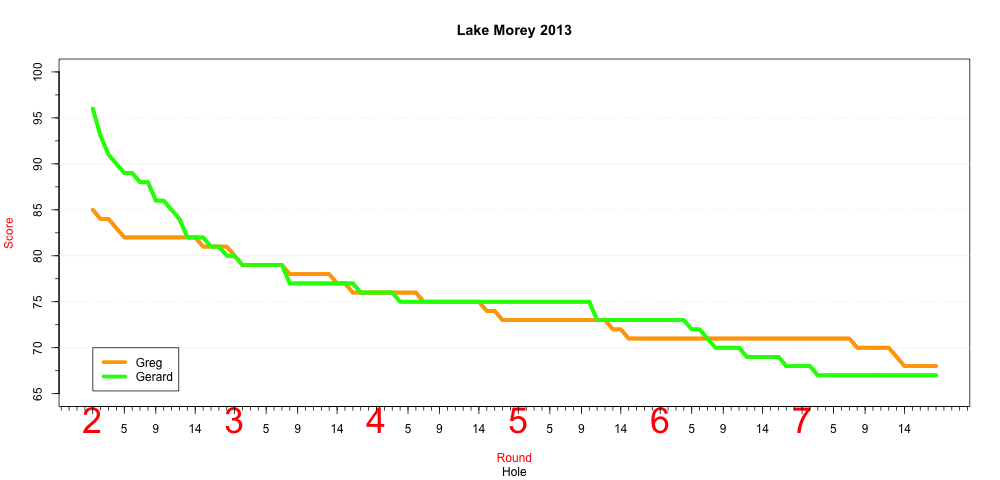 Cheers.
Cheers.
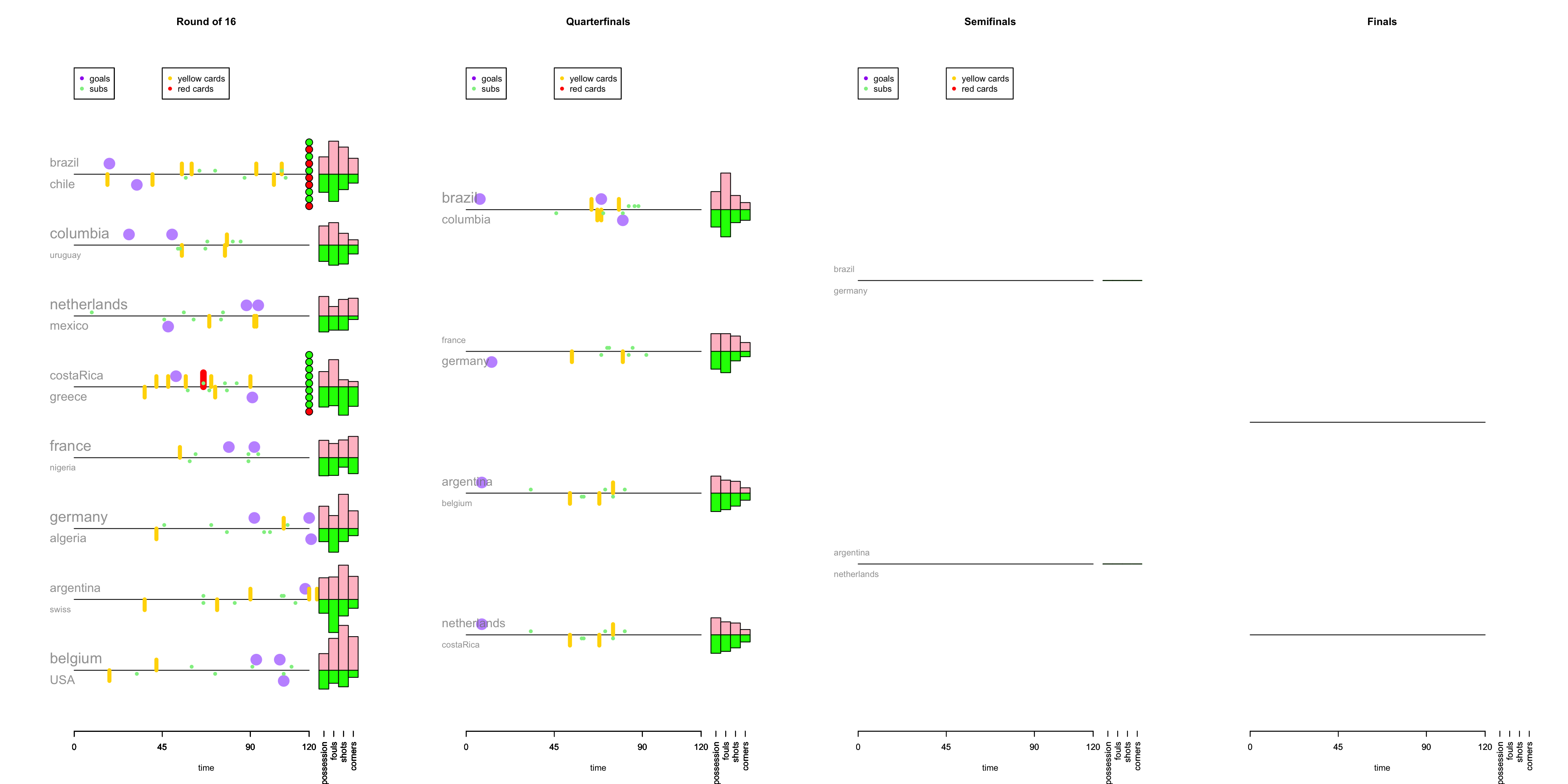
World Cup Data Viz Update
Some notes about the knockout stage:
- 3 of the 4 quarterfinal matches featured goals in the first fifteen minutes of the game.
- 20 of 28 penalty kick in the tie-breakers have been goals.
- Belgium had 38 (!) shots agains the USA. Tim Howard.
- So far teams have averaged 0.96 goals per game in the knock-out stage.
- 50% (6 of 12) of games in the knock-out stage were tied at the end of regulation. 3 of those games went to a shootout.



Some interesting notes:
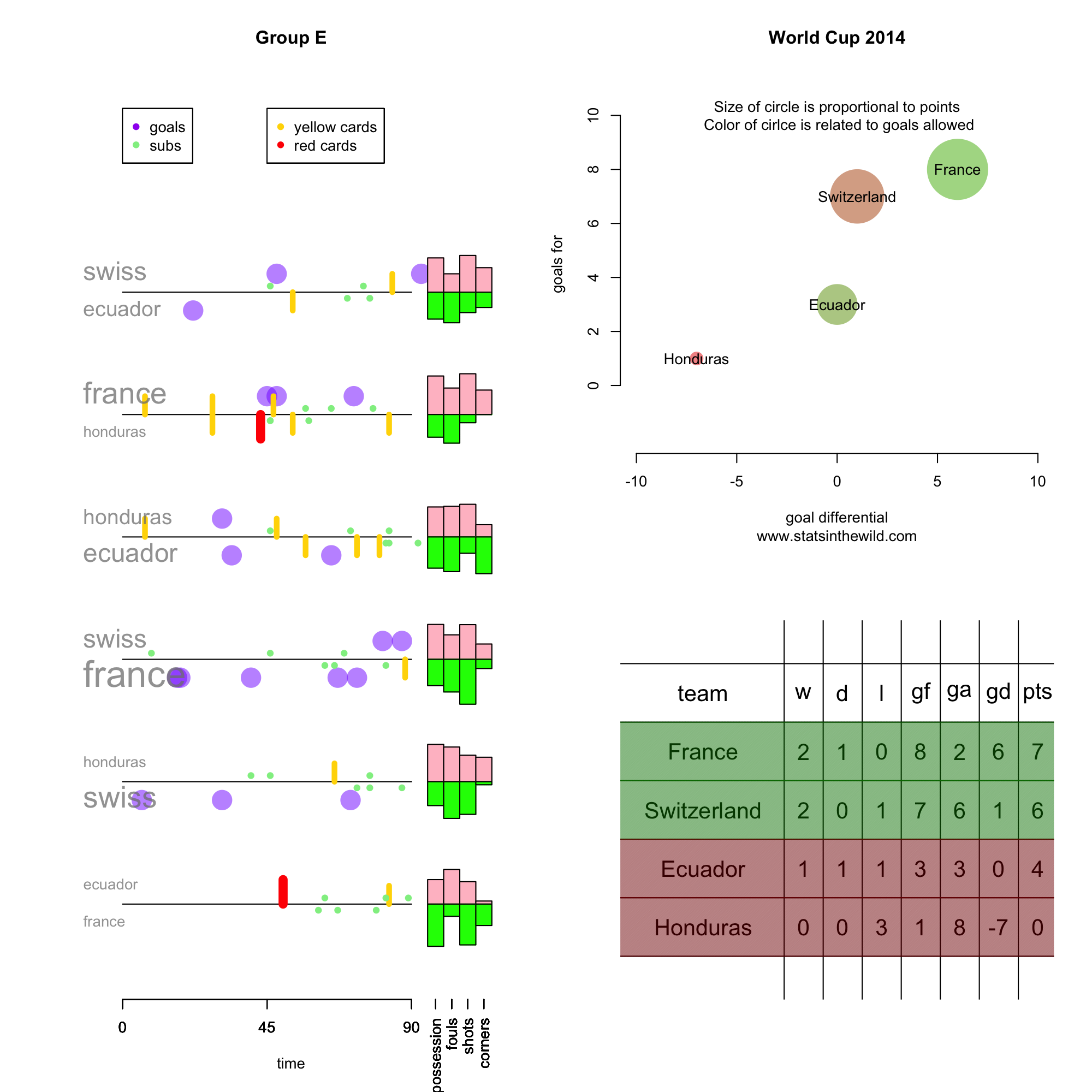
- Greece scored only 2 goals and still advanced out of the group stage. They were also the only team to advance to the knock-out stage with a negative goal differential.
- Switzerland allowed 6 goals and still made it out of the group stage.
- Cameroon, Australia, and Honduras were the only teams that did not score a point. Cameroon was -8 in goal differential, which was the worst in the group stages.
- Croatia scored 6 goals and did not advance.
- Italy, Ecuador, and Russia allowed only 3 goals in the group stage, but none of them managed to advance to the knock-out round.
- Every team with a positive goal differential advanced to the knock-out stage. Uruguay, Nigeria, and the USA advanced with goal differentials of 0.
- Ecuador and Portugal both scored 4 points, but neither advanced.
- The Netherlands scored 10 goals in the group stage.
- Teams averaged 1.42 goals per game in the group stage.
- Teams scored 0.8 goals less in regulation in the knock-out stages compared to the group stage.
- Belgium was the only to team to win their group without scoring the most goals in their group.
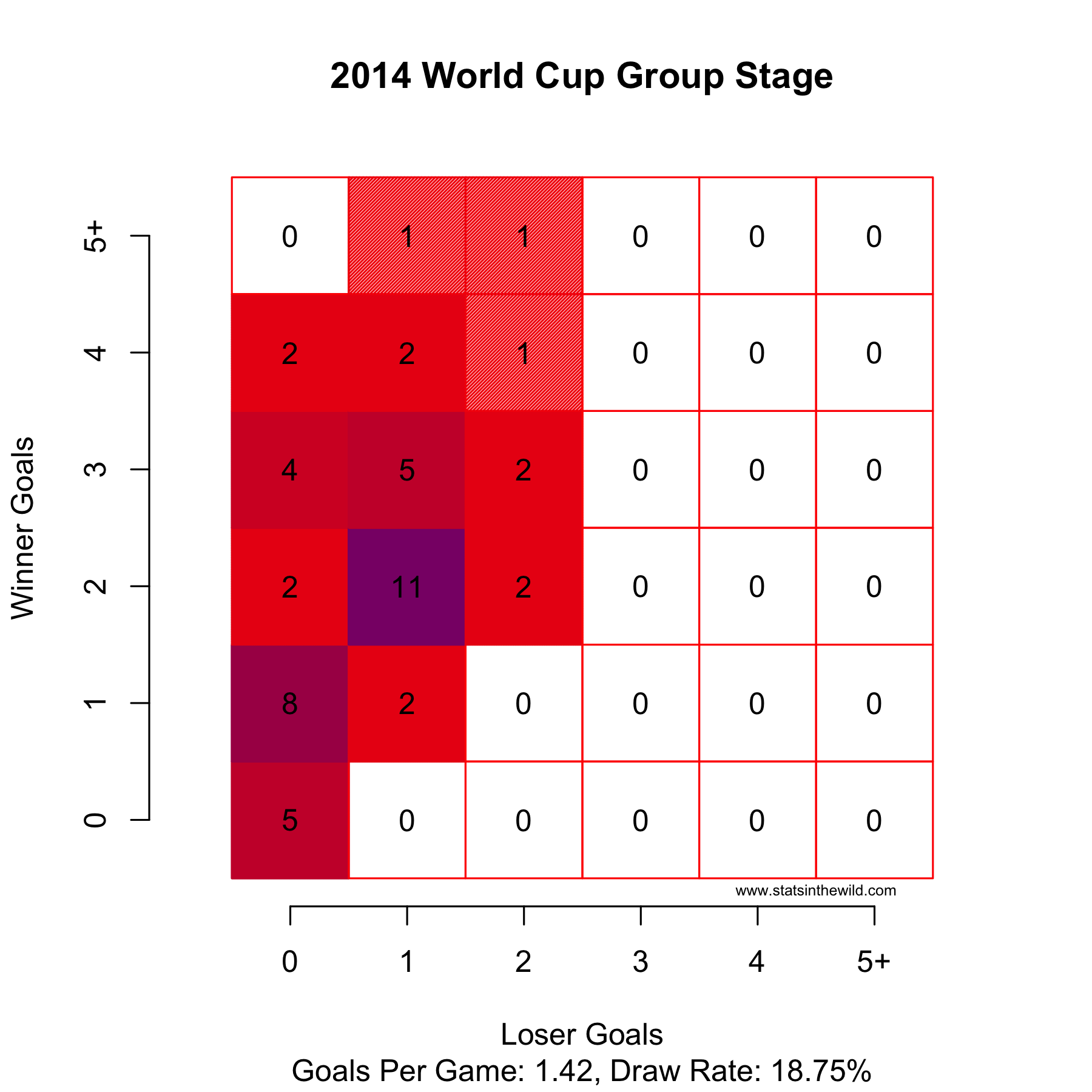
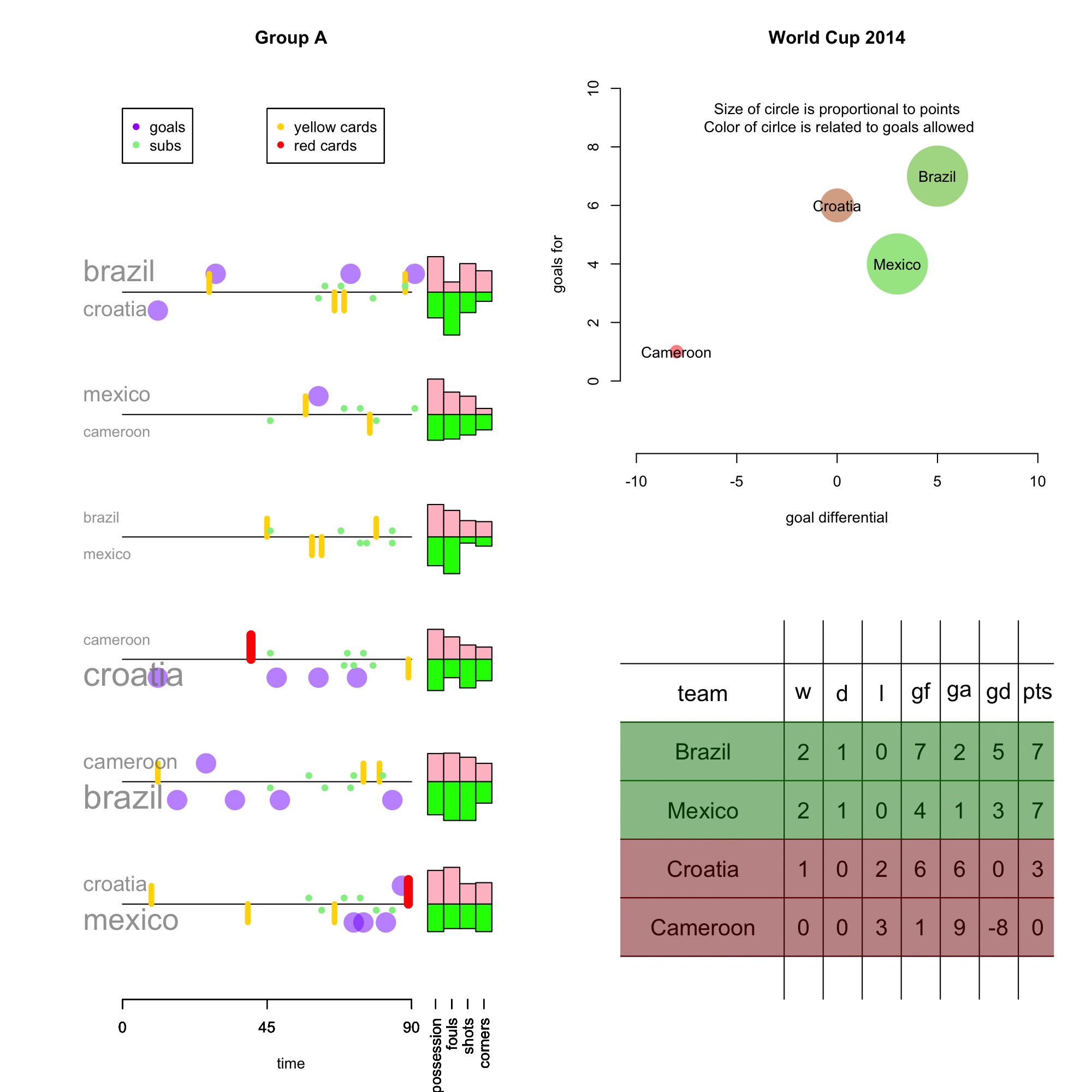

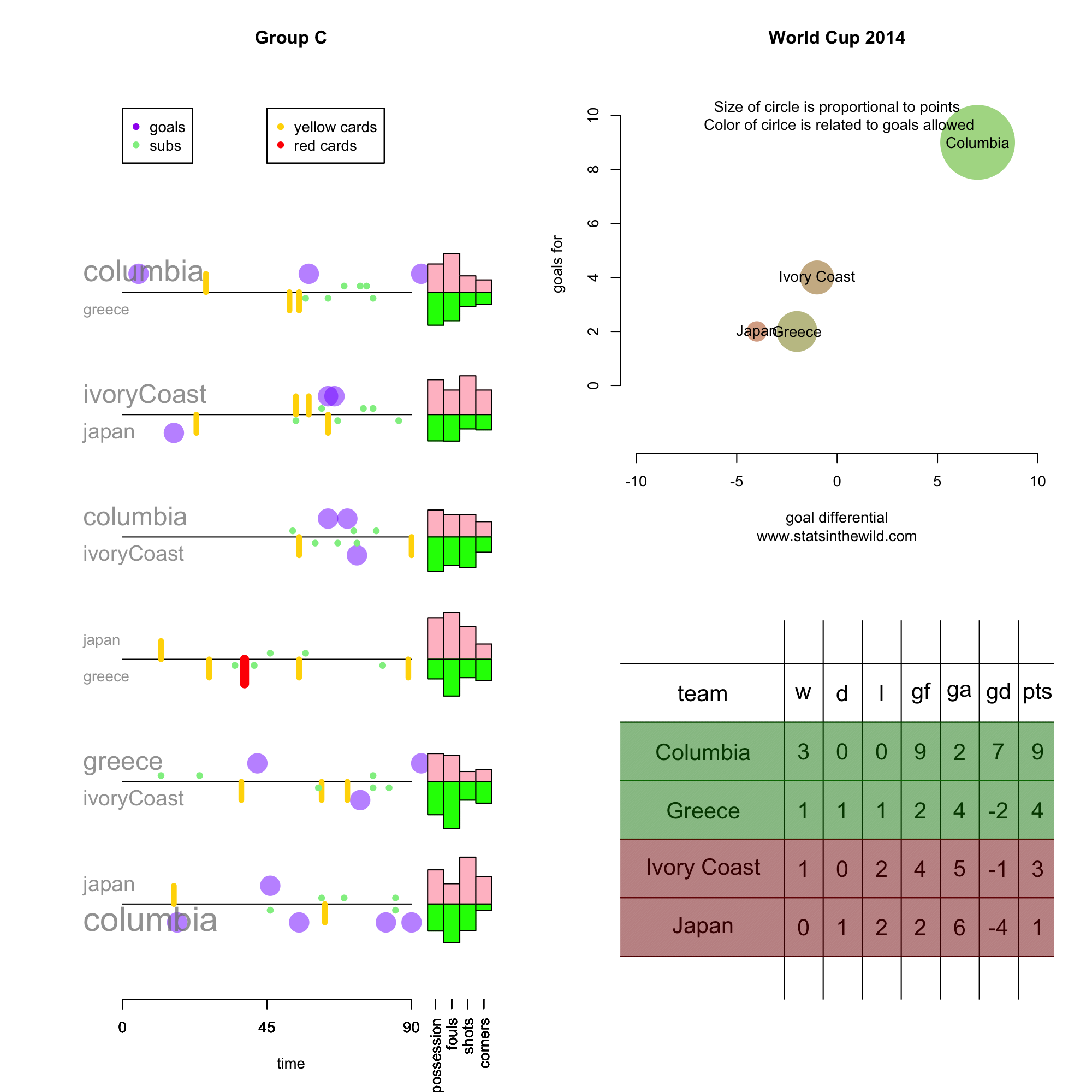




So fix it…
Here is the third to last paragraph of the article How the Portugal Draw Boosts the U.S.’s World Cup Advancement Odds from FiveThirtyEight (emphasis added):
So, why I do I say that our 76 percent figure might slightly underestimate the Americans’ chances? One reason is technical rather than soccer-related: Our simulation was programmed to resolve ties beyond goals scored and goal differential randomly, rather than looking at head-to-head results, because the head-to-head tiebreaker so rarely comes into play. But if a Ghanaian win in Brasilia and an American loss in Recife come by exactly the same scoreline — e.g. Ghana 3, Portugal 2, and Germany 3, U.S. 2 — that would trigger the head-to-head tiebreaker. The probability of such an outcome is low, but it means the simulator has slightly underestimated the U.S.’s advancement prospects, perhaps by 1 or 2 percent.
I understand that this rarely occurs, but why not add the one or two lines of code needed to add this? If they really believe that their probabilities are off and could be easily fixed, why not do it?
Cheers.

{kind=link}
{kind=link}
{kind=link}
{kind=link}