Category Archives: Uncategorized
Tons of goals; Very few draws
I don’t follow soccer/futbol too closely, but I love the World Cup (USA! USA! USA!). I’ve been watching quite a bit of it, and there are two things that are standing out to me.
- It seems like there are a ton of goals being scored
- It seems like there are fewer draws than usual
So I went and checked. So far for the 2014 World Cup, the games are averaging 1.57 goals per game and only 7.14% (1 out of 14) of games have ended in a draw. Compare this with the average number of goals scored in the last three World Cups 1.05, 1.22, 1.35 in 2010, 2006, and 2002, respectively. Also compare with the draw rates of 29.17%, 22.92%,29.17% from 2010, 2006, and 2002, respectively.
So, up to this point the summary of the World Cup is tons of goals, very few draws. Even American’s can enjoy that!
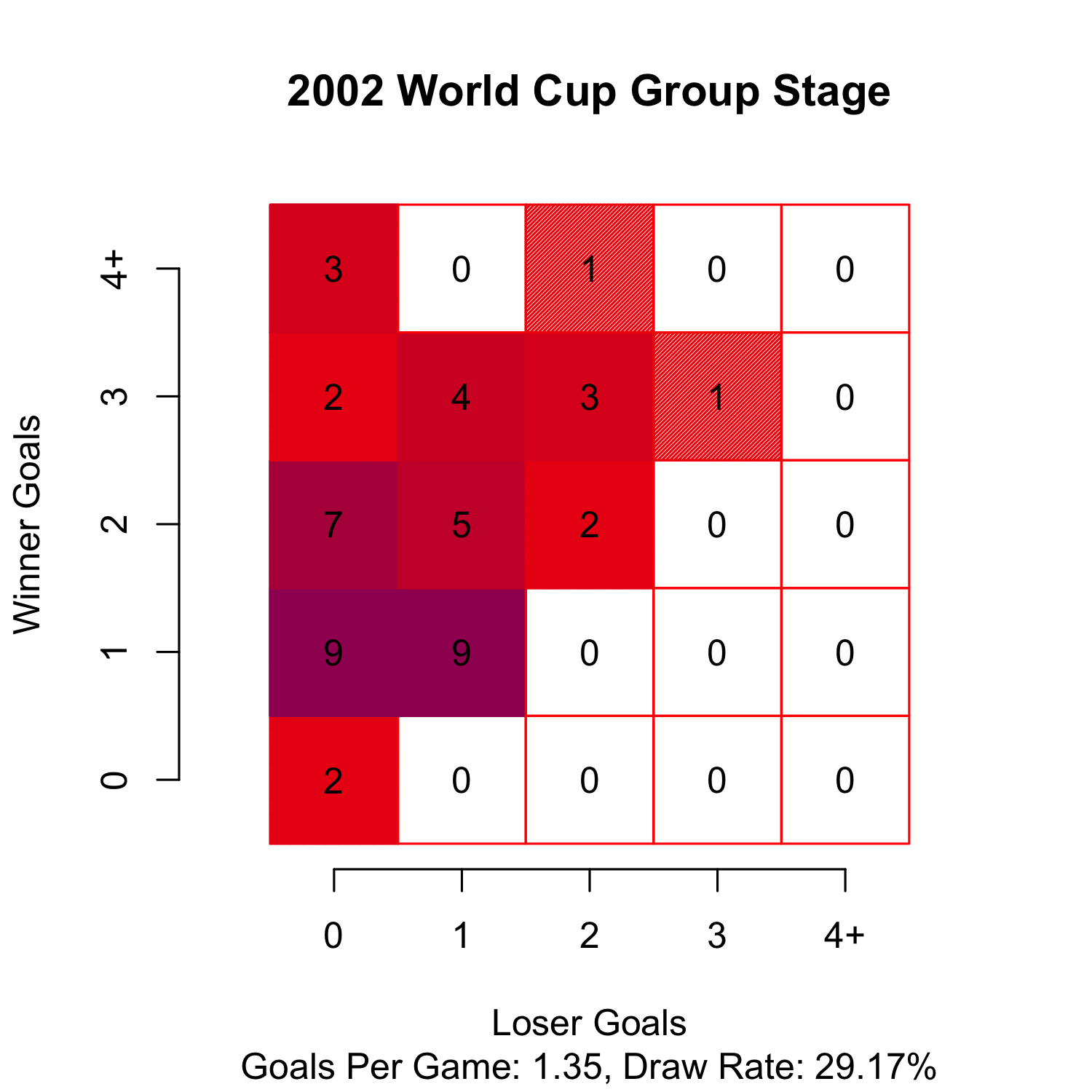
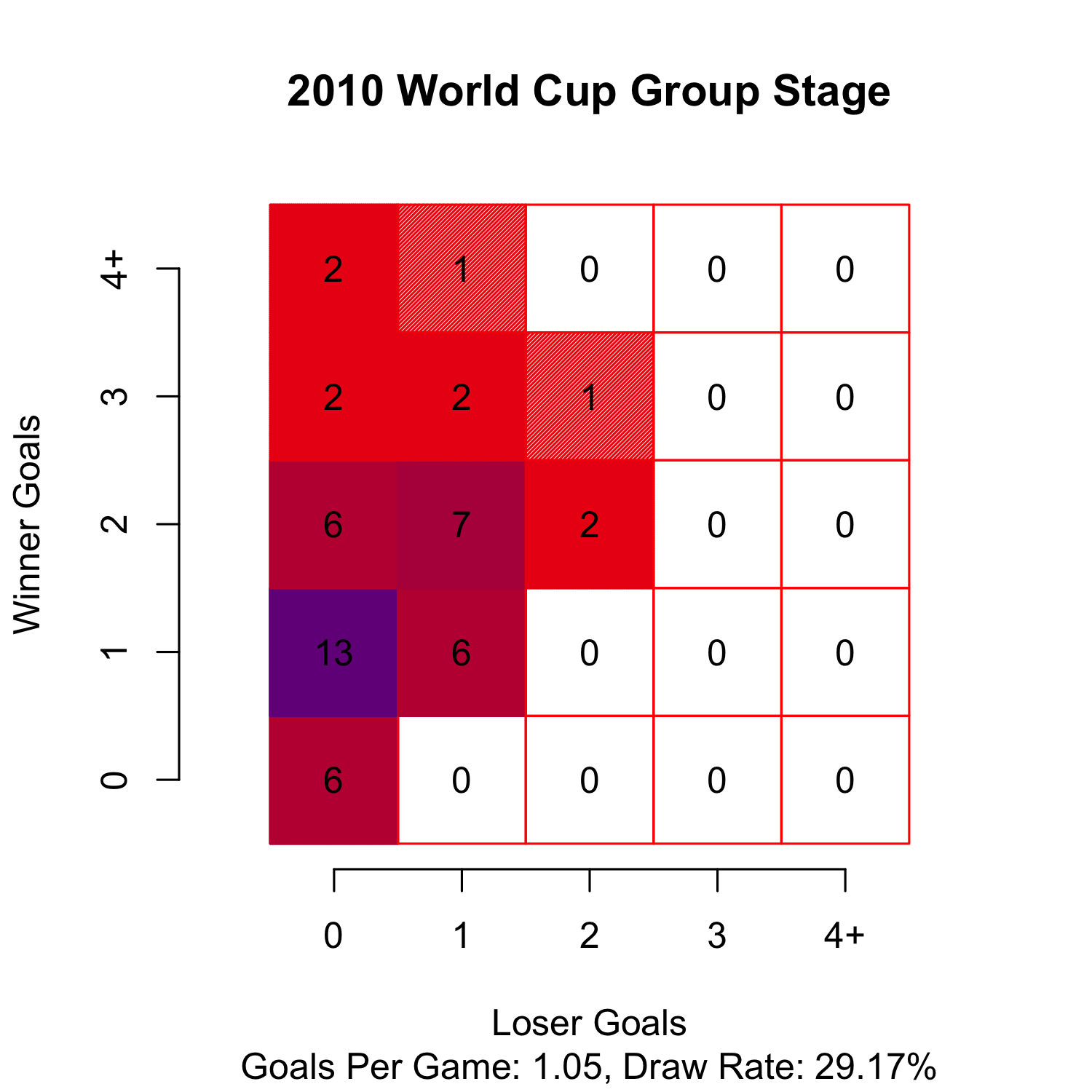


Cheers.
the hurricane name study gets worse
Science!
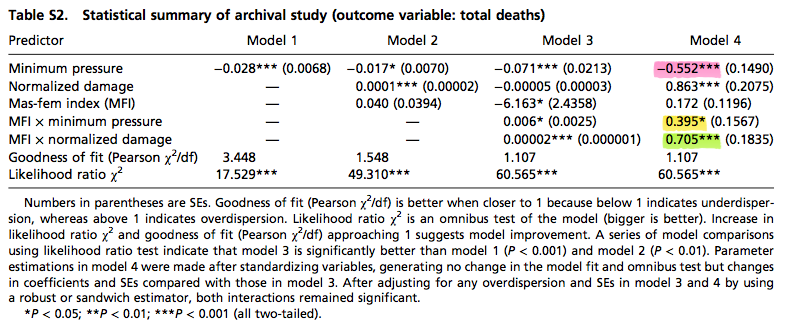
Hurricane Name Study, how I wish I could quit you. But an inquiry prompted me to look some more. Again, you can download the data yourself and replicate their key model, Model 4 above, using the half-tweet’s worth of code I included earlier.
The table isn’t in the paper, only their supplemental materials. Notice there are two significant interaction effects: one for the dollar damage of a hurricane (highlighted in green), and the other for the minimum pressure (highlighted in yellow). Both are severity measures. You might think that because both coefficients have the same sign, they both are consistent with the story that, as hurricanes become more severe, the death rate goes up faster for “female hurricanes” than “male hurricanes.”
Hey, wait! Don’t more severe hurricanes have lower minimum pressure? Why, yes. You can confirm this several ways, but notice how the pink coefficient for the…
View original post 292 more words
Creating HexBin Plots
Exploring Baseball Data with R
Creating HexBin Plots
Kirk Goldsberry has attracted a lot of attention with his “geographic” shot charts for NBA players. These are examples of “hexbin” plots. Luckily, the hexbin package for R provides the ability to quickly similar plots. Here, we’ll show how to create a few quick hexbin plots using the MLBAM data.
Carlos Gomez has been in the news recently – let’s focus on him. We’ll start by loading the openWAR data for 2013, and locating Gomez’s MLBAM player ID. [Of course, you can also do this with a web query.]
From this subset, we can compute how many balls Gomez caught while playing CF in 2013. In the MLBAM data, the fielderId field contains the ID of the player who first fielded the ball.
This confirms that Gomez caught each of these 390 balls. Note that we can also calculate statistics when Gomez was playing CF, including the…
View original post 328 more words
Death Maps
On Tuesday, Slate published the article “You Live in Alabama. Here’s How You’re Going to Die.” that contained some interesting maps. I liked this one the best. Florida and accidents is the least surprising thing I have ever seen.

While this is an interesting map, doing things like this at the state level is not the best. I know it’s probably the simplest way to do things and there are lots of data separated by state, but these maps at the county level would be much more interesting imho.
Cheers.
Talent acquisition and the post-steroid era
As of yesterday, Buster Posey, Jacoby Ellsbury, and Ryan Howard were each ranked between 90th and 100th in OPS among all MLB baseball players. That threesome is making $58 million in 2014 alone, with a whopping $338 million owed to them by their teams after this season ends.
Such a trifecta of seemingly awful contracts got me thinking about team performance in the post steroid era. Bad & expensive contracts have always been a part of sports, in particular baseball, but with performance perhaps more variable now than in prior era’s, are general managers with cash to spend having a more difficult time doing so?
Here’s a graph of team payroll and win percentages for each team in the 2004, 2009, and 2014 seasons.
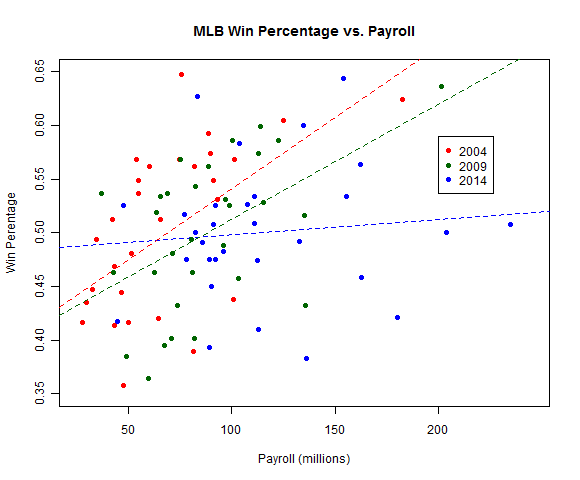 MLB Win percentage by salary
MLB Win percentage by salary
Teams spending money in 2004 posted much higher win percentages, on average, than frugal teams. This association was weaker in 2009, and there is…
View original post 126 more words
Quacks
I like this quote:
Legislators in Washington state refuse to live in a world where only the wealthy can afford care from poorly trained health care providers who practice unproven medicine.
It’s from the article “Quacking All the Way to the Bank“.
Cheers.
Basic text analysis of presidential inaugural addresses
My summer goal was to blog more. So here I go. Two posts in two days. No way can I keep that pace up.
So I recently had the chance to teach a short course on web scraping and text analysis. One of my examples scraped data from presidential inaugural speeches. With this corpus (a new word that I learned), we can look at things like the most often used words
findFreqTerms(presTDM,300) [1] "can" "government" "great" "may" "must" "people" [7] "shall" "states" "upon" "will"
I then used to demonstrate some clustering methods. For instance, using hierarchical clustering will produce a dendrogram like the following:
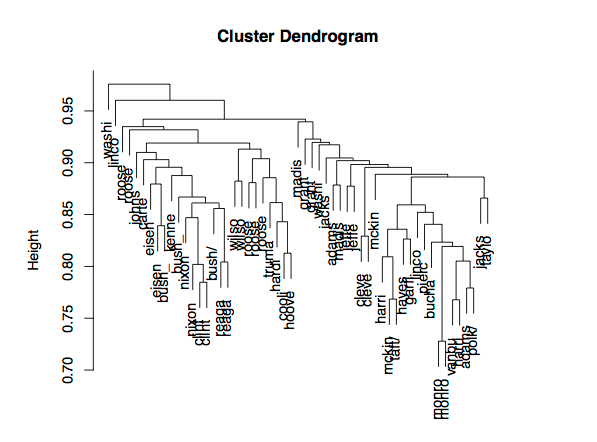
The data to make this plot consists of a large sparse matrix with each row representing a speech and each column corresponding to a word with a count of the number of times the j-th word was used in the i-th speech. In this way you can measure the distance between each speech and do clustering.
As it turned out I had some political science students in the class and they pointed out to me that it looks like there are two big groups consisting of recent presidents and less recent presidents. So the question came up as to what was the difference?
So on the fly I write some code to test for differences in word use between the older and newer presidents. What we ended up doing was a two sample t-test for each word split by old or new president. These groups were created by putting all presidents prior to and including Taft into group 1 and all presidents after Taft into group 2.
We then recorded the p-value for each of these tests. If we used a level alpha=0.05 for family wise error rate, a Bonferroni corrected threshold would be 5.604753e-06. Three words reached this conservative cut-off: duties, world, and public. The top 100 words (I removed january and march since those are dates of the speeches and don’t really count) based on p-values appear below.
word pval
duties duties 4.629343e-07
world world 1.095059e-06
public public 4.391972e-06
subject subject 9.420443e-06
today today 1.256848e-05
america america 1.568912e-05
know know 1.787979e-05
live live 2.668409e-05
life life 2.895837e-05
regard regard 3.306319e-05
lives lives 4.643304e-05
interests interests 4.711251e-05
foreign foreign 4.855870e-05
objects objects 4.948200e-05
functions functions 5.686164e-05
help help 6.199250e-05
work work 6.522966e-05
present present 6.926184e-05
attention attention 7.776694e-05
peculiar peculiar 9.771913e-05
civil civil 1.016519e-04
states states 1.018945e-04
views views 1.055752e-04
condition condition 1.336558e-04
unity unity 1.368429e-04
general general 1.475924e-04
virtue virtue 1.920787e-04
come come 1.976854e-04
enjoyed enjoyed 2.605138e-04
happily happily 2.605138e-04
settled settled 2.628839e-04
discharge discharge 2.770679e-04
opportunity opportunity 2.981866e-04
god god 3.266714e-04
old old 3.336640e-04
execute execute 3.378849e-04
new new 3.598835e-04
vision vision 3.746672e-04
opinion opinion 3.992428e-04
wise wise 4.278589e-04
centuries centuries 5.185043e-04
enable enable 5.608008e-04
americans americans 6.192669e-04
official official 6.339651e-04
original original 6.970246e-04
station station 7.021808e-04
strict strict 7.021808e-04
constitution constitution 7.404890e-04
therefore therefore 7.463164e-04
state state 7.476751e-04
way way 8.538455e-04
gods gods 8.743461e-04
nation nation 8.817792e-04
object object 8.921927e-04
women women 8.977030e-04
none none 9.039120e-04
portion portion 9.805345e-04
patriotic patriotic 9.942662e-04
freedom freedom 1.020410e-03
liberal liberal 1.155951e-03
importance importance 1.160502e-03
together together 1.174523e-03
judgment judgment 1.285434e-03
vice vice 1.285803e-03
faithful faithful 1.343211e-03
existence existence 1.419454e-03
gratitude gratitude 1.457342e-03
cultivate cultivate 1.464136e-03
attained attained 1.464136e-03
entertained entertained 1.464136e-03
scarcely scarcely 1.580568e-03
economic economic 1.597010e-03
several several 1.617976e-03
may may 1.725435e-03
build build 1.781003e-03
poverty poverty 1.781003e-03
intercourse intercourse 1.782419e-03
circumstances circumstances 1.812426e-03
dignity dignity 1.820683e-03
born born 2.016370e-03
patriotism patriotism 2.039916e-03
need need 2.077322e-03
resolve resolve 2.203595e-03
administration administration 2.250915e-03
blessings blessings 2.253577e-03
formed formed 2.277049e-03
officers officers 2.315975e-03
administered administered 2.365768e-03
assembled assembled 2.365768e-03
heretofore heretofore 2.365768e-03
historic historic 2.511711e-03
exists exists 2.662722e-03
felt felt 2.763852e-03
domestic domestic 2.773740e-03
debt debt 2.835649e-03
disposition disposition 2.850068e-03
policy policy 2.851784e-03
Of course this test was only looking at differences and it doesn’t answer which direction the difference is in. Let’s look at a few of the top words (Note: group2 is more recent president):
t.test((m[,colnames(m)=="duties"])~group)
Welch Two Sample t-test
data: (m[, colnames(m) == "duties"]) by group
t = 6.1796, df = 34.719, p-value = 4.629e-07
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
1.651399 3.267956
sample estimates:
mean in group 1 mean in group 2
2.709677 0.250000
t.test((m[,colnames(m)=="world"])~group)
Welch Two Sample t-test
data: (m[, colnames(m) == "world"]) by group
t = -6.4016, df = 24.814, p-value = 1.095e-06
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-10.86082 -5.57198
sample estimates:
mean in group 1 mean in group 2
1.741935 9.958333
t.test((m[,colnames(m)=="public"])~group)
Welch Two Sample t-test
data: (m[, colnames(m) == "public"]) by group
t = 5.1556, df = 49.692, p-value = 4.392e-06
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
2.921318 6.651263
sample estimates:
mean in group 1 mean in group 2
6.16129 1.37500
The word “duties” was used on average about 2.7 times in older inaugural addresses and only .25 times in the newer speeches.
The word “world” was used on average about 1.74 times per inaugural address among the old speeches, whereas in the newer speeches it was used on average about 9.96 times per address. Below is a break down of who was using the word “world”.
m[,colnames(m)=="world"]
washi washi adams jeffe jeffe madis madis monro monro adams jacks jacks vanbu
1 0 3 2 2 2 1 0 2 1 0 2 2
harri polk/ taylo pierc bucha linco linco grant grant hayes garfi cleve harri
2 5 0 3 3 1 1 1 2 2 2 1 0
cleve mckin mckin roose taft/ wilso wilso hardi cooli hoove roose roose roose
0 6 2 3 2 2 6 23 13 14 6 1 3
roose truma eisen eisen kenne johns nixon nixon carte reaga reaga bush/ clint
2 22 14 14 8 7 12 16 5 8 14 10 18
clint bush_ bush_
10 3 8
Finally, the word “public” was used about 6.16 times in the old addresses and only 1.375 times in the new address.
Further down the list, the word “god” shows up (Note: all words have been forced to lowercase).
t.test((m[,colnames(m)=="god"])~group)
Welch Two Sample t-test
data: (m[, colnames(m) == "god"]) by group
t = -3.9492, df = 38.157, p-value = 0.0003267
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.4558401 -0.7914717
sample estimates:
mean in group 1 mean in group 2
0.7096774 2.3333333
And we we look at which group is using the word more often, we see that in the older addresses the word “god” was used on average about .71 times per address, whereas in the newer speeches it is used 2.33 times per address. If we break this down by speech it’s even more interesting.
> m[,colnames(m)=="god"]
washi washi adams jeffe jeffe madis madis monro monro adams jacks jacks vanbu
0 0 0 0 0 0 0 0 1 0 0 0 0
harri polk/ taylo pierc bucha linco linco grant grant hayes garfi cleve harri
0 0 0 1 1 0 5 1 0 0 3 1 2
cleve mckin mckin roose taft/ wilso wilso hardi cooli hoove roose roose roose
2 2 2 0 1 1 1 4 1 2 2 0 1
roose truma eisen eisen kenne johns nixon nixon carte reaga reaga bush/ clint
2 2 4 1 2 3 5 2 1 4 8 2 1
clint bush_ bush_
1 3 3
The word “god” wasn’t mentioned in any of the first 8 presidential inaugural addresses and only 3 times in the first 18. In fact it wasn’t until Lincoln where the word god was used more than once. Every president since Garfield has mentioned the word “god” in their inaugural address at least once with the exception of Teddy Roosevelt and FDR (second address). And Reagan used the word “god” 8 times in his second inaugural address.
I also though the words “drugs” and “work” were interesting so I added those here:
m[,colnames(m)=="drugs"]
washi washi adams jeffe jeffe madis madis monro monro adams jacks jacks vanbu
0 0 0 0 0 0 0 0 0 0 0 0 0
harri polk/ taylo pierc bucha linco linco grant grant hayes garfi cleve harri
0 0 0 0 0 0 0 0 0 0 0 0 0
cleve mckin mckin roose taft/ wilso wilso hardi cooli hoove roose roose roose
0 0 0 0 0 0 0 0 0 0 0 0 0
roose truma eisen eisen kenne johns nixon nixon carte reaga reaga bush/ clint
0 0 0 0 0 0 0 0 0 0 0 1 0
clint bush_ bush_
2 0 0
m[,colnames(m)=="work"]
washi washi adams jeffe jeffe madis madis monro monro adams jacks jacks vanbu
0 0 0 1 0 0 1 3 0 1 0 0 1
harri polk/ taylo pierc bucha linco linco grant grant hayes garfi cleve harri
1 0 0 0 1 0 1 0 0 1 1 1 1
cleve mckin mckin roose taft/ wilso wilso hardi cooli hoove roose roose roose
2 2 1 1 7 2 0 2 2 1 3 3 0
roose truma eisen eisen kenne johns nixon nixon carte reaga reaga bush/ clint
2 4 6 2 1 3 0 4 2 7 5 7 6
clint bush_ bush_
8 4 6
And finally, here’s a word cloud of all the words used in the inaugural addresses because everyone loves word clouds.

Cheers.
Geordi La Forge
One day at lunch in high school the following exchange took place:
My friend: “Who plays the blind guy on Star Trek?”
Me: “It’s LeVar Burton….but you don’t have to take my word for it.”
You can make this joke relevant again for another generation by donating to my boy LeVar and bringing back Reading Rainbow.
Also, here is the Reading Rainbow theme music.
Cheers.
The next step
Fellow Kaggle champion Mike Lopez has announced that he will be teaching at Skidmore next year! And apparently “investing” his money at the track. Good luck (in both your endeavors), Mike!
This news is about a month old, but I hadn’t updated it on the blog.
I accepted a position as an assistant professor of statistics at Skidmore College.
This will be my school year.

This will be my summer (kind of).

